6.0 KiB
| date created | date updated | tags | share | link | |
|---|---|---|---|---|---|
| 2024-08-15 17:30 | 2024-10-30 17:46 |
|
true | false |
过程
MCP使用以太网连接平台,长时间挂机后会提示HAL_ETH_GetDMAError错误。
使用wireshark抓包,可以发现以太网有像桩端发送数据,但是没有收到应答。
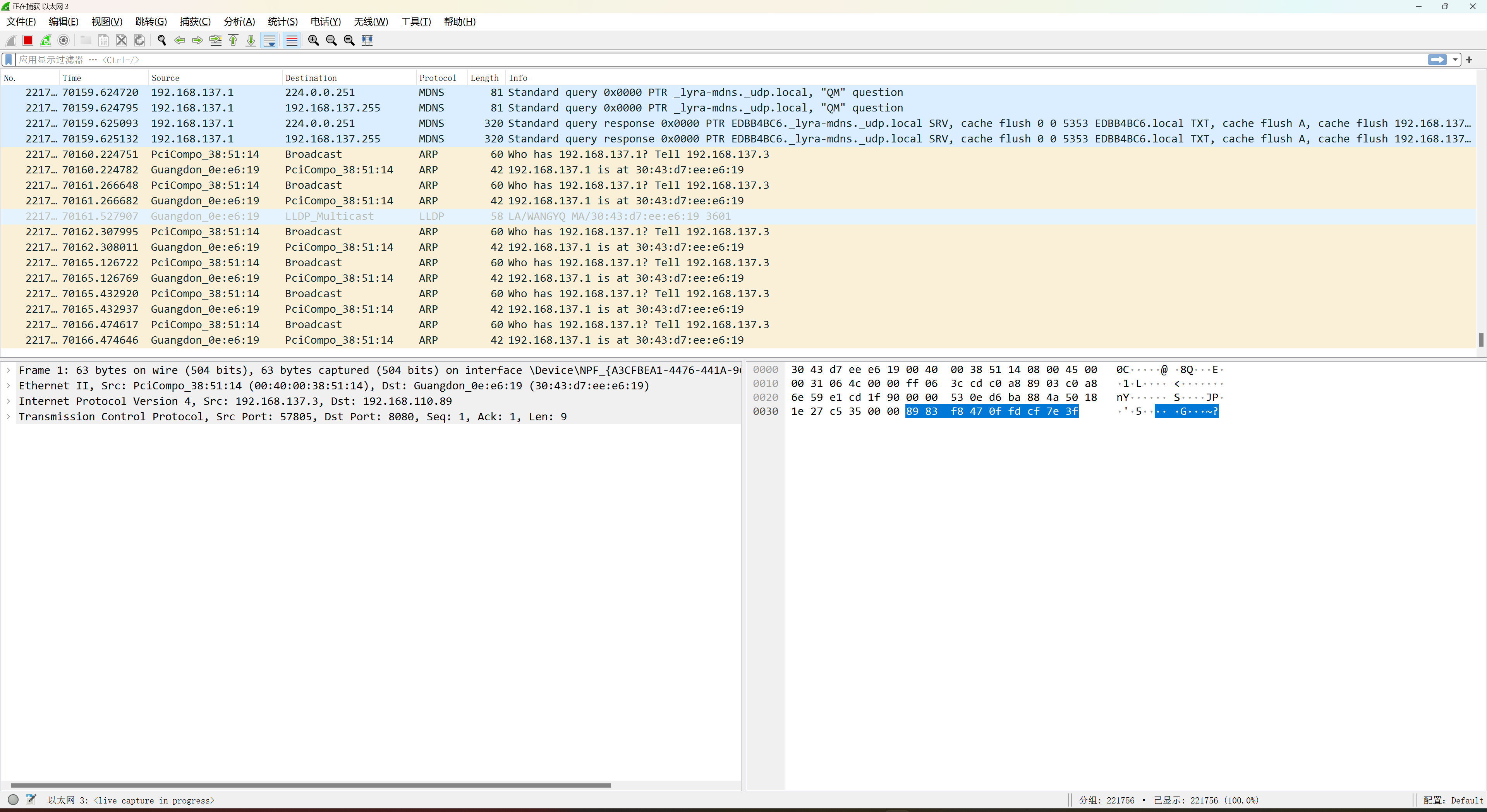 ping网关,可以看到网关有接收到桩端发送的ARP请求,并且有应答,但是桩没有接收到报文。
ping网关,可以看到网关有接收到桩端发送的ARP请求,并且有应答,但是桩没有接收到报文。
在ST论坛看到一样的问题,解决办法是在HAL_ETH_ErrorCallback中断回调中去清除寄存器。
void HAL_ETH_ErrorCallback(ETH_HandleTypeDef *heth)
{
if((HAL_ETH_GetDMAError(heth) & ETH_DMACSR_RBU) == ETH_DMACSR_RBU)
{
printf( "ETH DMA Rx Error\n" );
osSemaphoreRelease(RxPktSemaphore);
// Clear RBUS ETHERNET DMA flag
heth->Instance->DMACSR = ETH_DMACSR_RBU;
// Resume DMA reception
heth->Instance->DMACRDTPR = 0;
}
if((HAL_ETH_GetDMAError(heth) & ETH_DMACSR_TBU) == ETH_DMACSR_TBU)
{
printf( "ETH DMA Tx Error\n" );
osSemaphoreRelease(TxPktSemaphore);
//Clear TBU flag to resume processing
heth->Instance->DMACSR = ETH_DMACSR_TBU;
//Instruct the DMA to poll the transmit descriptor list
heth->Instance->DMACTDTPR = 0;
}
}
以及在上层的LWIP中修改tcp接收窗口,这个没有用,查看LWIP的值一直都是他修复后的数值。
尝试了上面的方法后发现没有什么作用。选择先规避这个问题,在上面的ERROR中断回调中增加以太网的重新初始化。
if((HAL_ETH_GetDMAError(heth) & ETH_DMACSR_TBU) == ETH_DMACSR_TBU)
{
printf( "ETH DMA Tx Error\n" );
osSemaphoreRelease(TxPktSemaphore);
//Clear TBU flag to resume processing
heth->Instance->DMACSR = ETH_DMACSR_TBU;
//Instruct the DMA to poll the transmit descriptor list
heth->Instance->DMACTDTPR = 0;
HAL_ETH_DeInit(&EthHandle);
HAL_ETH_Init(&EthHandle);
}
测试了下,虽然会导致websocket连接断掉,但是可以接受。但是测试使用以太网升级固件的时候,因为数据量大,产生错包的概率增加,重新初始化后又进入了RX ERROR中,导致无限重新初始化。
然后再ST的github上搜索ETH_DMACSR_RBU,找到了一个已解决的方案,就是把上面的清除的动作放到rx的while线程中执行,RX ERROR 中断中不执行任何操作。
void HAL_ETH_ErrorCallback(ETH_HandleTypeDef *heth)
{
if((HAL_ETH_GetDMAError(heth) & ETH_DMACSR_RBU) == ETH_DMACSR_RBU)
{
osSemaphoreRelease(RxPktSemaphore);
}
if((HAL_ETH_GetDMAError(heth) & ETH_DMACSR_TBU) == ETH_DMACSR_TBU)
{
osSemaphoreRelease(TxPktSemaphore);
}
}
static void ethernet_watchdog(void) {
if ((ETH->DMACSR & ETH_DMACSR_RBU) == ETH_DMACSR_RBU )
{
// Clear RBUS ETHERNET DMA flag
ETH->DMACSR = ETH_DMACSR_RBU;
// Resume DMA reception
ETH->DMACRDTPR = 0;
}
if ((ETH->DMACSR & ETH_DMACSR_TBU) == ETH_DMACSR_TBU )
{
// Clear RBUS ETHERNET DMA flag
ETH->DMACSR = ETH_DMACSR_TBU;
// Resume DMA reception
ETH->DMACTDTPR = 0;
}
}
void ethernetif_input( void * pvParameters )
{
struct pbuf *p;
for( ;; )
{
. . .
ethernet_watchdog();
}
}
此时,测试上面的使用以太网升级固件的问题,发现可以升级成功。但是挂测了一段时间后发现又回到了原点,进入RX ERROR后,以太网又无法使用了。
再ethernet_watchdog函数中添加打印,发现以太网的状态分为3个阶段,第一个阶段是正常的使用,第二个阶段是ETH_DMACSR_RBU被置位,然后又被DMA看门狗清除,不断的重复这个过程,但是此时的以太网是可以使用的。第三个阶段是进入了RX ERROR的回调中,以太网彻底无法使用。
在ST的官方论坛中,有类似的现象,上面没有确切的解决办法,call fae问原厂拿解决方法。
把stm32h7xx_hal_eth.c文件中的一段代码: tailidx = (descidx + 1U) % ETH_RX_DESC_CNT; 改成: tailidx = (ETH_RX_DESC_CNT + descidx - 1U) % ETH_RX_DESC_CNT; 目的是将tail pointer指向前一个描述符,而不是后一个描述符。 说这样有助于更好地提高效率和阻止丢包。
在H5中找到类似的函数,将描述符从后一个改为前一个后,发现这个改动会产生死机
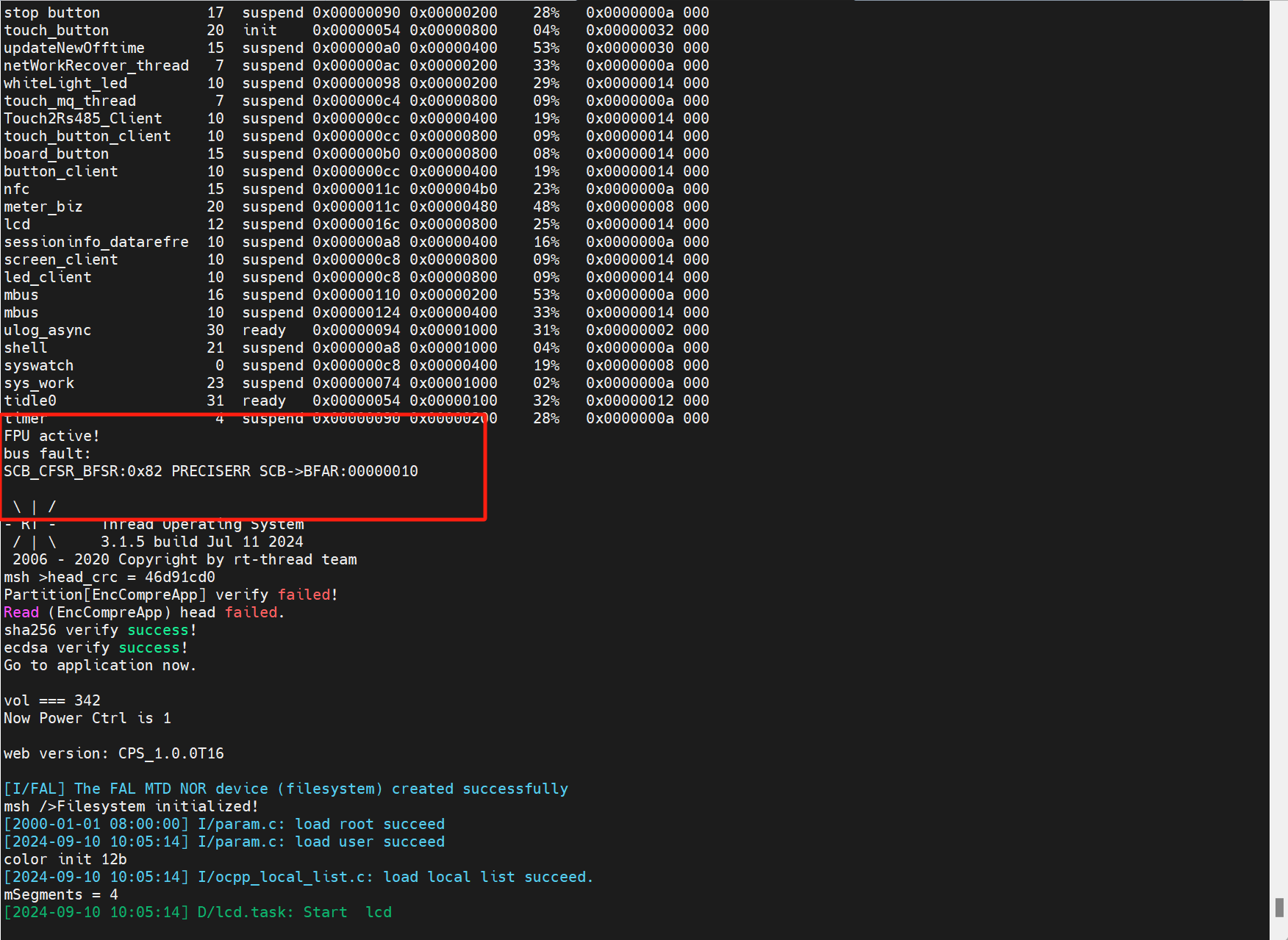
因为上面的思路是提高以太网的效率,之前都是想解决RX ERROR产生的DMA Buffer被占用完的问题,于是打开DCACHE,想提高以太网的效率,看能否产生一样的效果。
打开DCACHE后,挂测一天,发现虽然还是会产生ETH_DMACSR_RBU的情况,但是可以自恢复,且多数情况下不会与平台断联。
但是并没有完全解决这个问题,ST论坛的出了关于h5解决上面的那个问题的方法了,和fae给出的方法是一样的。。这说明我的hal库和官方现有的不一致,更新hal库,挂测2天发现问题解决了。
总结
- 尽量不要使用STM32CubeMX生成的代码,直接去github上找新的代码。在fae给我他的解决方案的时候,我是有怀疑过hal库不是最新的,还重新用STM32CubeMX生成一遍后和原有的代码比较。没想到的是他的源就不是最新,只能怀疑是h5和h7的写法不同。不然这个问题应该很早就能解决。STM32CubeMX只适合拿来入门,真正要拿来工程使用的还是得自己搭建。
- 对以太网底层的原理理解得不深刻,不能只依赖hal库的修复,太过被动了。后续有时间得过下hal库的以太网代码,增加理解。