mirror of
https://github.com/jackyzha0/quartz.git
synced 2026-03-23 22:45:41 -05:00
[PUBLISHER] Merge #56
* PUSH NOTE : 使用Quartz部署obsidian.md * DELETE FILE : content/Obsidian/OCPP/Everest/EVerest-core.md * DELETE FILE : content/Obsidian/OCPP/Everest/EVerest-framework.md * DELETE FILE : content/Obsidian/OCPP/Everest/EVerest-timer.md * DELETE FILE : content/Obsidian/后端/spring.md * DELETE FILE : content/Obsidian/后端/动态代理.md * DELETE FILE : content/Obsidian/后端/反射机制.md * DELETE FILE : content/Obsidian/工具/AI/使用chatpdf辅助翻译.md * DELETE FILE : content/Obsidian/工具/flac批量转换成mp3.md * DELETE FILE : content/Obsidian/工具/笔记/Obsidian配置.md * DELETE FILE : content/Obsidian/工具/笔记/dataview的简单使用.md * DELETE FILE : content/Obsidian/工具/笔记/使用Quartz部署obsidian.md * DELETE FILE : content/Obsidian/工具/笔记/卢曼的卡片盒笔记法:Zettelkasten Method.md * DELETE FILE : content/Obsidian/环境搭建/wsl/CitrineOS安装.md * DELETE FILE : content/Obsidian/环境搭建/调试/MPU版本烧写.md * DELETE FILE : content/Obsidian/编程模型及方法/DAO.md * DELETE FILE : content/Obsidian/编程模型及方法/MVC.md * DELETE FILE : content/Obsidian/编程模型及方法/ORM.md * DELETE FILE : content/Obsidian/编程模型及方法/依赖注入.md * DELETE FILE : content/Obsidian/编程语言/Java/JDBC.md * DELETE FILE : content/Obsidian/踩过的坑/以太网BUG解决过程记录.md * DELETE FILE : content/Obsidian/踩过的坑/客户平台无法连接问题.md * DELETE FILE : content/_index.md
This commit is contained in:
parent
4462b9cb7c
commit
7e21c9b514
@ -1,8 +1,14 @@
|
|||||||
---
|
---
|
||||||
{"date":"2024-10-29 12:11","updated":"2024-12-05 16:16","tags":["笔记","分享"],"share":"true","link":"false","publish":true,"PassFrontmatter":true}
|
date: 2024-10-29 12:11
|
||||||
|
updated: 2024-12-05 17:23
|
||||||
|
tags:
|
||||||
|
- 笔记
|
||||||
|
- 分享
|
||||||
|
share: "true"
|
||||||
|
link: "false"
|
||||||
|
publish: true
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
最近想整一个obsidian的笔记分享,[参考](https://lazyjoy.12123123.xyz/%E5%85%B6%E5%AE%83%E8%B5%84%E6%BA%90/Obsidian/Quartz%E4%B8%8EEnveloppe%E6%8F%92%E4%BB%B6%E7%BB%93%E5%90%88%E5%8A%A9%E5%8A%9BObsidian%E6%90%AD%E5%BB%BA%E6%95%B0%E5%AD%97%E8%8A%B1%E5%9B%AD/)
|
最近想整一个obsidian的笔记分享,[参考](https://lazyjoy.12123123.xyz/%E5%85%B6%E5%AE%83%E8%B5%84%E6%BA%90/Obsidian/Quartz%E4%B8%8EEnveloppe%E6%8F%92%E4%BB%B6%E7%BB%93%E5%90%88%E5%8A%A9%E5%8A%9BObsidian%E6%90%AD%E5%BB%BA%E6%95%B0%E5%AD%97%E8%8A%B1%E5%9B%AD/)
|
||||||
|
|
||||||
## Quartz部署
|
## Quartz部署
|
||||||
@ -54,11 +60,11 @@ Cloudflare应该会在大约一分钟内为我们的网站部署一个版本。
|
|||||||
|
|
||||||
Obsidian充当了Quartz的功能强大的内容编辑器。 在Quartz存储库的`.gitignore`文件中,可以发现其中有`.obsidian`和`private`,前者是忽略Obsidian配置及插件相关的文件,后者大概是暗示我们可以将一些私密的笔记放在`private`目录下,避免在上传到Github上时不小心把隐私相关的笔记也传上去了,防止在存储库具有公开访问权限时引起不必要的麻烦。 此种工作流要求我们把笔记空间当作Quartz项目的一部分,并且笔记的结构和网站上保持一致。
|
Obsidian充当了Quartz的功能强大的内容编辑器。 在Quartz存储库的`.gitignore`文件中,可以发现其中有`.obsidian`和`private`,前者是忽略Obsidian配置及插件相关的文件,后者大概是暗示我们可以将一些私密的笔记放在`private`目录下,避免在上传到Github上时不小心把隐私相关的笔记也传上去了,防止在存储库具有公开访问权限时引起不必要的麻烦。 此种工作流要求我们把笔记空间当作Quartz项目的一部分,并且笔记的结构和网站上保持一致。
|
||||||
|
|
||||||
> [!NOTE|+aside-l]
|
|
||||||
> 使用[quartz-syncer](https://github.com/saberzero1/quartz-syncer)发布也可以
|
|
||||||
|
|
||||||
此外,该项目在本地[安装](https://link.zhihu.com/?target=https%3A//quartz.jzhao.xyz/upgrading)、[编译](https://link.zhihu.com/?target=https%3A//quartz.jzhao.xyz/build)、[部署](https://link.zhihu.com/?target=https%3A//quartz.jzhao.xyz/hosting%23self-hosting)以及本地与远程存储库之间进行[同步](https://link.zhihu.com/?target=https%3A//quartz.jzhao.xyz/setting-up-your-GitHub-repository)以及从官方存储库[获取代码更新](https://link.zhihu.com/?target=https%3A//quartz.jzhao.xyz/upgrading)方面做的比较完善,感兴趣的可以参考官方文档在本地进行尝试,本文工作流涉及不到本地处理,如果不需要对项目代码进行较大修改,可以暂时略过这方面的操作。 借助Obsidian插件Enveloppe可以实现笔记库与网站的分离。
|
此外,该项目在本地[安装](https://link.zhihu.com/?target=https%3A//quartz.jzhao.xyz/upgrading)、[编译](https://link.zhihu.com/?target=https%3A//quartz.jzhao.xyz/build)、[部署](https://link.zhihu.com/?target=https%3A//quartz.jzhao.xyz/hosting%23self-hosting)以及本地与远程存储库之间进行[同步](https://link.zhihu.com/?target=https%3A//quartz.jzhao.xyz/setting-up-your-GitHub-repository)以及从官方存储库[获取代码更新](https://link.zhihu.com/?target=https%3A//quartz.jzhao.xyz/upgrading)方面做的比较完善,感兴趣的可以参考官方文档在本地进行尝试,本文工作流涉及不到本地处理,如果不需要对项目代码进行较大修改,可以暂时略过这方面的操作。 借助Obsidian插件Enveloppe可以实现笔记库与网站的分离。
|
||||||
|
|
||||||
|
> [!NOTE|+aside-r] Enveloppe插件
|
||||||
|
> 使用[quartz-syncer](https://github.com/saberzero1/quartz-syncer)发布也可以
|
||||||
|
|
||||||
## Enveloppe配置
|
## Enveloppe配置
|
||||||
|
|
||||||
### 说明
|
### 说明
|
||||||
@ -1,718 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2025-03-05 10:33
|
|
||||||
updated: 2025-03-11 14:40
|
|
||||||
tags: Everest,ocpp
|
|
||||||
link:
|
|
||||||
publish: true
|
|
||||||
share: true
|
|
||||||
---
|
|
||||||
|
|
||||||
# 项目依赖
|
|
||||||
|
|
||||||
阅读CMakeLists.txt文件可以知道,项目EVerest依赖于多个组件:
|
|
||||||
|
|
||||||
1. everest-cmake - 项目的构建系统工具
|
|
||||||
2. Boost库 - 使用了filesystem、program_options、system和thread组件
|
|
||||||
3. [[./EVerest-framework|EVerest-framework]] - 核心框架
|
|
||||||
4. everest-sunspec - 太阳能相关组件
|
|
||||||
5. everest-modbus - Modbus通信协议支持
|
|
||||||
6. everest-ocpp - 开放充电点协议(Open Charge Point Protocol)支持
|
|
||||||
7. everest-openv2g - 电动汽车到电网(V2G)通信支持
|
|
||||||
8. PalSigslot - 信号槽库
|
|
||||||
9. fsm - 有限状态机
|
|
||||||
10. slac - 可能是Signal Level Attenuation Characterization的缩写,用于电力线通信
|
|
||||||
11. pugixml - XML解析库
|
|
||||||
|
|
||||||
这些项目通过EDM管理,当EDM不使能时,cmake会去查找本地安装的路径。
|
|
||||||
|
|
||||||
# 架构图
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
graph LR
|
|
||||||
A[EVerest Core] --> B[模块系统]
|
|
||||||
A --> C[接口定义]
|
|
||||||
A --> D[构建系统]
|
|
||||||
|
|
||||||
B --> B1[通信模块]
|
|
||||||
B --> B2[协议模块]
|
|
||||||
B --> B3[硬件接入模块]
|
|
||||||
B --> B4[能源管理模块]
|
|
||||||
|
|
||||||
B1 --> B1a[SerialCommHub]
|
|
||||||
B1 --> B1b[SLAC]
|
|
||||||
|
|
||||||
B2 --> B2a[OCPP]
|
|
||||||
B2 --> B2b[ISO15118]
|
|
||||||
|
|
||||||
B3 --> B3a[GenericPowermeter]
|
|
||||||
|
|
||||||
B2b --> B2b1[PyJosev-SECC]
|
|
||||||
B2b --> B2b2[PyEvJosev-EVCC]
|
|
||||||
|
|
||||||
C --> C1[YAML接口定义]
|
|
||||||
C1 --> C1a[kvs.yaml]
|
|
||||||
C1 --> C1b[energy.yaml]
|
|
||||||
C1 --> C1c[auth.yaml]
|
|
||||||
C1 --> C1d[slac.yaml]
|
|
||||||
C1 --> C1e[power.yaml]
|
|
||||||
|
|
||||||
D --> D1[CMake系统]
|
|
||||||
D --> D2[ev-project-bootstrap]
|
|
||||||
```
|
|
||||||
|
|
||||||
# 核心组件解析
|
|
||||||
|
|
||||||
## 模块系统
|
|
||||||
|
|
||||||
EVerest采用模块化设计,每个模块专注于特定功能
|
|
||||||
|
|
||||||
### GenericPowermeter
|
|
||||||
|
|
||||||
```sh
|
|
||||||
# 通过ModbusRTU协议连接和读取电表数据
|
|
||||||
# 支持AC和DC电表,通过配置文件描述寄存器映射
|
|
||||||
# 读取数据包括:能量、功率、电压、电流、频率等
|
|
||||||
```
|
|
||||||
|
|
||||||
### SerialCommHub
|
|
||||||
|
|
||||||
```c
|
|
||||||
// 串行通信中心,处理Modbus通信
|
|
||||||
response = modbus.txrx(target_device_id, tiny_modbus::FunctionCode::READ_MULTIPLE_HOLDING_REGISTERS,
|
|
||||||
first_register_address, num_registers_to_read);
|
|
||||||
```
|
|
||||||
|
|
||||||
### OCPP模块
|
|
||||||
|
|
||||||
```c
|
|
||||||
// 实现开放充电点协议
|
|
||||||
bool ocpp_1_6_charge_pointImpl::handle_restart() {
|
|
||||||
std::lock_guard<std::mutex>(this->m);
|
|
||||||
mod->charging_schedules_timer->interval(std::chrono::seconds(this->mod->config.PublishChargingScheduleIntervalS));
|
|
||||||
bool success = mod->charge_point->restart();
|
|
||||||
if (success) {
|
|
||||||
this->mod->ocpp_stopped = false;
|
|
||||||
}
|
|
||||||
return success;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### ISO15118实现
|
|
||||||
|
|
||||||
#### PyJosev - 充电站侧实现(SECC)
|
|
||||||
|
|
||||||
```c
|
|
||||||
async def secc_handler_main_loop(module_config: dict):
|
|
||||||
# 启动ISO 15118 SECC控制器
|
|
||||||
config = Config()
|
|
||||||
patch_josev_config(config, module_config)
|
|
||||||
sim_evse_controller = await SimEVSEController.create()
|
|
||||||
await SECCHandler(
|
|
||||||
exi_codec=ExificientEXICodec(), evse_controller=sim_evse_controller, config=config
|
|
||||||
).start(config.iface)
|
|
||||||
```
|
|
||||||
|
|
||||||
#### PyEvJosev - 车辆侧实现(EVCC)
|
|
||||||
|
|
||||||
```c
|
|
||||||
async def evcc_handler_main_loop(module_config: dict):
|
|
||||||
# 启动ISO 15118 EVCC控制器
|
|
||||||
iface = determine_network_interface(module_config['device'])
|
|
||||||
evcc_config = EVCCConfig()
|
|
||||||
patch_josev_config(evcc_config, module_config)
|
|
||||||
await EVCCHandler(
|
|
||||||
evcc_config=evcc_config,
|
|
||||||
iface=iface,
|
|
||||||
exi_codec=ExificientEXICodec(),
|
|
||||||
ev_controller=SimEVController(evcc_config),
|
|
||||||
).start()
|
|
||||||
```
|
|
||||||
|
|
||||||
## 接口定义系统
|
|
||||||
|
|
||||||
EVerest使用YAML文件定义模块间接口,采用统一的格式定义命令和变量
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
# 接口示例 (kvs.yaml - 键值存储接口)
|
|
||||||
description: This interface defines a simple key-value-store interface
|
|
||||||
cmds:
|
|
||||||
store:
|
|
||||||
description: This command stores a value under a given key
|
|
||||||
arguments:
|
|
||||||
key:
|
|
||||||
description: Key to store the value for
|
|
||||||
type: string
|
|
||||||
pattern: ^[A-Za-z0-9_.]*$
|
|
||||||
```
|
|
||||||
|
|
||||||
# OCPP模块
|
|
||||||
|
|
||||||
以OCPP模块为例,学习EVerest-core的构建到执行的过程。
|
|
||||||
|
|
||||||
## 架构流程图
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
graph TD
|
|
||||||
A[OCPP模块初始化] --> B[模块构造与依赖注入]
|
|
||||||
B --> C[init调用]
|
|
||||||
C --> D[ready调用]
|
|
||||||
D --> E[启动ChargePoint服务]
|
|
||||||
|
|
||||||
E --> F1[处理OCPP核心功能]
|
|
||||||
E --> F2[提供令牌验证]
|
|
||||||
E --> F3[提供令牌授权]
|
|
||||||
|
|
||||||
F1 --> G1[通信控制]
|
|
||||||
F1 --> G2[配置管理]
|
|
||||||
F1 --> G3[数据传输]
|
|
||||||
F1 --> G4[安全事件]
|
|
||||||
|
|
||||||
G1 --> H1[启动/停止连接]
|
|
||||||
G1 --> H2[重新连接]
|
|
||||||
|
|
||||||
G2 --> I1[获取配置]
|
|
||||||
G2 --> I2[设置配置]
|
|
||||||
G2 --> I3[监控配置变更]
|
|
||||||
|
|
||||||
G3 --> J1[DataTransfer请求/响应]
|
|
||||||
|
|
||||||
G4 --> K1[安全事件通知]
|
|
||||||
|
|
||||||
subgraph 定时任务
|
|
||||||
L1[充电计划定时器]
|
|
||||||
end
|
|
||||||
|
|
||||||
E --> L1
|
|
||||||
```
|
|
||||||
|
|
||||||
## 核心组件解析
|
|
||||||
|
|
||||||
### 模块结构与初始化
|
|
||||||
|
|
||||||
#### 依赖注入机制
|
|
||||||
|
|
||||||
OCPP模块的初始化过程包括 构造函数中的依赖注入和init/ready方法:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// OCPP.hpp - 模块构造函数
|
|
||||||
OCPP(const ModuleInfo& info, Everest::MqttProvider& mqtt_provider,
|
|
||||||
std::unique_ptr<ocpp_1_6_charge_pointImplBase> p_main,
|
|
||||||
std::unique_ptr<auth_token_validatorImplBase> p_auth_validator,
|
|
||||||
std::unique_ptr<auth_token_providerImplBase> p_auth_provider,
|
|
||||||
std::vector<std::unique_ptr<evse_managerIntf>> r_evse_manager,
|
|
||||||
std::vector<std::unique_ptr<external_energy_limitsIntf>> r_connector_zero_sink,
|
|
||||||
std::unique_ptr<reservationIntf> r_reservation, std::unique_ptr<authIntf> r_auth,
|
|
||||||
std::unique_ptr<systemIntf> r_system, std::unique_ptr<evse_securityIntf> r_security,
|
|
||||||
Conf& config) :
|
|
||||||
ModuleBase(info),
|
|
||||||
mqtt(mqtt_provider),
|
|
||||||
p_main(std::move(p_main)),
|
|
||||||
p_auth_validator(std::move(p_auth_validator)),
|
|
||||||
p_auth_provider(std::move(p_auth_provider)),
|
|
||||||
r_evse_manager(std::move(r_evse_manager)),
|
|
||||||
r_connector_zero_sink(std::move(r_connector_zero_sink)),
|
|
||||||
r_reservation(std::move(r_reservation)),
|
|
||||||
r_auth(std::move(r_auth)),
|
|
||||||
r_system(std::move(r_system)),
|
|
||||||
r_security(std::move(r_security)),
|
|
||||||
config(config){};
|
|
||||||
```
|
|
||||||
|
|
||||||
这个构造函数显示该模块的复杂性,它需要多个接口交互,包括:
|
|
||||||
|
|
||||||
- 提供的接口: OCPP充电点、认证令牌验证、认证令牌提供
|
|
||||||
- 依赖的接口: EVSE管理器、能源限制、预约、认证、系统和安全
|
|
||||||
|
|
||||||
这种注入方式遵循依赖倒置原则,通过接口而非具体实现进行交互,提高了系统的解耦性和可测试性。
|
|
||||||
|
|
||||||
#### 初始化流程
|
|
||||||
|
|
||||||
OCPP模块的初始化分为两个阶段
|
|
||||||
|
|
||||||
##### 初始化阶段 (init)
|
|
||||||
|
|
||||||
- 创建ChargePoint实例
|
|
||||||
- 配置数据库路径
|
|
||||||
- 设置安全参数
|
|
||||||
- 建立MQTT连接
|
|
||||||
- 初始化定时器
|
|
||||||
|
|
||||||
##### 就绪阶段 (ready)
|
|
||||||
|
|
||||||
- 启动WebSocket连接
|
|
||||||
- 设置充电计划定时器
|
|
||||||
- 注册回调函数
|
|
||||||
- 订阅相关主题
|
|
||||||
|
|
||||||
##### 初始化代码示例
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
void OCPP::init() {
|
|
||||||
// 配置文件路径处理
|
|
||||||
ocpp_share_path = std::filesystem::path(this->info.paths.share);
|
|
||||||
|
|
||||||
// 创建ChargePoint核心对象
|
|
||||||
charge_point = std::make_unique<ocpp::v16::ChargePoint>(
|
|
||||||
/* 配置参数 */
|
|
||||||
);
|
|
||||||
}
|
|
||||||
|
|
||||||
void OCPP::ready() {
|
|
||||||
// 设置充电计划定时器
|
|
||||||
charging_schedules_timer = std::make_unique<Everest::SteadyTimer>(
|
|
||||||
[this](){
|
|
||||||
// 定时发布充电计划
|
|
||||||
this->publish_charging_schedules(
|
|
||||||
this->charge_point->get_composite_schedule(
|
|
||||||
std::chrono::seconds(this->config.PublishChargingScheduleDurationS)
|
|
||||||
)
|
|
||||||
);
|
|
||||||
}
|
|
||||||
);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### ChargePoint核心组件
|
|
||||||
|
|
||||||
ChargePoint是OCPP模块的核心组件,负责所有OCPP通信:
|
|
||||||
|
|
||||||
- WebSocket管理:建立和维护与CSMS的WebSocket连接
|
|
||||||
- 消息序列化:将OCPP消息转换为JSON格式
|
|
||||||
- 会话管理:处理认证和会话状态
|
|
||||||
- 事务处理:管理充电事务的开始、进行和结束
|
|
||||||
- 配置管理:处理配置请求和更新
|
|
||||||
|
|
||||||
### 接口实现
|
|
||||||
|
|
||||||
#### ocpp_1_6_charge_pointImpl
|
|
||||||
|
|
||||||
`ocpp_1_6_charge_pointImpl`类实现了OCPP 1.6协议的主要功能:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
bool ocpp_1_6_charge_pointImpl::handle_stop() {
|
|
||||||
std::lock_guard<std::mutex>(this->m);
|
|
||||||
mod->charging_schedules_timer->stop();
|
|
||||||
bool success = mod->charge_point->stop();
|
|
||||||
if (success) {
|
|
||||||
this->mod->ocpp_stopped = true;
|
|
||||||
}
|
|
||||||
return success;
|
|
||||||
}
|
|
||||||
|
|
||||||
bool ocpp_1_6_charge_pointImpl::handle_restart() {
|
|
||||||
std::lock_guard<std::mutex>(this->m);
|
|
||||||
mod->charging_schedules_timer->interval(std::chrono::seconds(this->mod->config.PublishChargingScheduleIntervalS));
|
|
||||||
bool success = mod->charge_point->restart();
|
|
||||||
if (success) {
|
|
||||||
this->mod->ocpp_stopped = false;
|
|
||||||
}
|
|
||||||
return success;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
数据转换函数示例:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
types::ocpp::KeyValue to_everest(const ocpp::v16::KeyValue& key_value) {
|
|
||||||
types::ocpp::KeyValue _key_value;
|
|
||||||
_key_value.key = key_value.key.get();
|
|
||||||
_key_value.read_only = key_value.readonly;
|
|
||||||
if (key_value.value.has_value()) {
|
|
||||||
_key_value.value = key_value.value.value().get();
|
|
||||||
}
|
|
||||||
return _key_value;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### auth_token_validatorImpl
|
|
||||||
|
|
||||||
实现令牌验证功能,将验证请求传递给OCPP后端:
|
|
||||||
|
|
||||||
```c
|
|
||||||
auth_token_validatorImpl::handle_validate_token(types::authorization::ProvidedIdToken& provided_token) {
|
|
||||||
if (provided_token.authorization_type == types::authorization::AuthorizationType::PlugAndCharge) {
|
|
||||||
return validate_pnc_request(provided_token);
|
|
||||||
} else {
|
|
||||||
return validate_standard_request(provided_token);
|
|
||||||
}
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
#### auth_token_providerImpl
|
|
||||||
|
|
||||||
提供令牌信息给其他模块:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// 伪代码
|
|
||||||
void auth_token_providerImpl::handle_get_token_info(const std::string& id_token, types::authorization::TokenInfo& token_info) {
|
|
||||||
auto response = mod->charge_point->get_token_info(id_token);
|
|
||||||
token_info.auth_status = convert_auth_status(response.status);
|
|
||||||
// 填充其他令牌信息
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
这里为什么没有具体的实现代码?
|
|
||||||
|
|
||||||
### 配置管理功能
|
|
||||||
|
|
||||||
模块支持全面的配置管理,包括获取、设置和监控配置:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// 获取配置
|
|
||||||
types::ocpp::GetConfigurationResponse ocpp_1_6_charge_pointImpl::handle_get_configuration_key(Array& keys) {
|
|
||||||
ocpp::v16::GetConfigurationRequest request;
|
|
||||||
std::vector<ocpp::CiString<50>> _keys;
|
|
||||||
for (const auto& key : keys) {
|
|
||||||
_keys.push_back(key);
|
|
||||||
}
|
|
||||||
request.key = _keys;
|
|
||||||
|
|
||||||
const auto response = this->mod->charge_point->get_configuration_key(request);
|
|
||||||
return to_everest(response);
|
|
||||||
}
|
|
||||||
|
|
||||||
// 监控配置变更
|
|
||||||
void ocpp_1_6_charge_pointImpl::handle_monitor_configuration_keys(Array& keys) {
|
|
||||||
for (const auto& key : keys) {
|
|
||||||
this->mod->charge_point->register_configuration_key_changed_callback(
|
|
||||||
key,
|
|
||||||
[this](const ocpp::v16::KeyValue key_value) {
|
|
||||||
this->publish_configuration_key(to_everest(key_value));
|
|
||||||
});
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### 安全机制
|
|
||||||
|
|
||||||
OCPP模块通过EvseSecurity类实现OCPP安全功能:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
class evse_securityImpl : public evse_securityImplBase {
|
|
||||||
public:
|
|
||||||
evse_securityImpl() = delete;
|
|
||||||
evse_securityImpl(Everest::ModuleAdapter* ev, const Everest::PtrContainer<EvseSecurity>& mod, Conf& config) :
|
|
||||||
evse_securityImplBase(ev, "main"), mod(mod), config(config){};
|
|
||||||
protected:
|
|
||||||
//伪代码
|
|
||||||
EvseSecurity(evse_securityIntf& r_security);
|
|
||||||
|
|
||||||
// 证书安装
|
|
||||||
ocpp::InstallCertificateResult install_ca_certificate(const std::string& certificate,
|
|
||||||
const ocpp::CaCertificateType& certificate_type) override;
|
|
||||||
|
|
||||||
// 证书删除
|
|
||||||
ocpp::DeleteCertificateResult
|
|
||||||
delete_certificate(const ocpp::CertificateHashDataType& certificate_hash_data) override;
|
|
||||||
|
|
||||||
// 证书验证
|
|
||||||
ocpp::InstallCertificateResult verify_certificate(const std::string& certificate_chain,
|
|
||||||
const ocpp::CertificateSigningUseEnum& certificate_type) override;
|
|
||||||
|
|
||||||
// 更多安全操作...
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
### 定时任务
|
|
||||||
|
|
||||||
模块使用定时器定期执行任务:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// 初始化定时器
|
|
||||||
charging_schedules_timer = std::make_unique<Everest::SteadyTimer>();
|
|
||||||
|
|
||||||
// 设置定时任务
|
|
||||||
charging_schedules_timer->interval(std::chrono::seconds(config.PublishChargingScheduleIntervalS));
|
|
||||||
charging_schedules_timer->start();
|
|
||||||
```
|
|
||||||
|
|
||||||
## 模块执行流程
|
|
||||||
|
|
||||||
### 启动流程
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
sequenceDiagram
|
|
||||||
participant E as EVerest框架
|
|
||||||
participant O as OCPP模块
|
|
||||||
participant CP as ChargePoint核心
|
|
||||||
participant EM as EVSE管理器
|
|
||||||
participant S as 安全模块
|
|
||||||
|
|
||||||
E->>O: 构造
|
|
||||||
O->>O: 依赖注入
|
|
||||||
E->>O: init()
|
|
||||||
O->>O: 初始化EVSE Ready Map
|
|
||||||
O->>EM: 订阅EVSE Ready事件
|
|
||||||
O->>O: 加载配置文件
|
|
||||||
O->>O: 创建ChargePoint实例
|
|
||||||
O->>S: 创建EvseSecurity包装
|
|
||||||
E->>O: ready()
|
|
||||||
O->>O: 初始化EVSE连接器映射
|
|
||||||
O->>CP: 注册多个回调函数
|
|
||||||
O->>CP: 启动WebSocket连接
|
|
||||||
O->>O: 设置充电计划定时器
|
|
||||||
```
|
|
||||||
|
|
||||||
1. 模块构造 - 依赖注入
|
|
||||||
2. init() - 初始化内部状态
|
|
||||||
3. ready() - 启动服务
|
|
||||||
4. 建立WebSocket连接
|
|
||||||
5. 注册回调函数
|
|
||||||
6. 开始定时任务
|
|
||||||
|
|
||||||
#### EVSE就绪映射初始化
|
|
||||||
|
|
||||||
模块使用 `evse_ready_map` 追踪所有EVSE的就绪状态:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
void OCPP::init_evse_ready_map() {
|
|
||||||
std::lock_guard<std::mutex> lk(this->evse_ready_mutex);
|
|
||||||
for (size_t evse_id = 1; evse_id <= this->r_evse_manager.size(); evse_id++) {
|
|
||||||
this->evse_ready_map[evse_id] = false;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
在init方法中,模块订阅每个EVSE的就绪状态:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
for (size_t evse_id = 1; evse_id <= this->r_evse_manager.size(); evse_id++) {
|
|
||||||
this->r_evse_manager.at(evse_id - 1)->subscribe_ready([this, evse_id](bool ready) {
|
|
||||||
std::lock_guard<std::mutex> lk(this->evse_ready_mutex);
|
|
||||||
if (ready) {
|
|
||||||
this->evse_ready_map[evse_id] = true;
|
|
||||||
this->evse_ready_cv.notify_one();
|
|
||||||
}
|
|
||||||
});
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
这种设计确保OCPP模块只有在所有EVSE都准备好后才会完全启动服务。
|
|
||||||
|
|
||||||
#### 配置文件处理
|
|
||||||
|
|
||||||
OCPP模块处理两种配置文件:
|
|
||||||
|
|
||||||
- 主配置文件:包含基本OCPP设置
|
|
||||||
- 用户配置文件:包含用户自定义设置
|
|
||||||
|
|
||||||
从哪里传进去的?
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// 寻找并加载主配置文件
|
|
||||||
auto configured_config_path = fs::path(this->config.ChargePointConfigPath);
|
|
||||||
if (!fs::exists(configured_config_path) && configured_config_path.is_relative()) {
|
|
||||||
configured_config_path = this->ocpp_share_path / configured_config_path;
|
|
||||||
}
|
|
||||||
|
|
||||||
// 解析JSON配置
|
|
||||||
std::ifstream ifs(config_path.c_str());
|
|
||||||
std::string config_file((std::istreambuf_iterator<char>(ifs)), (std::istreambuf_iterator<char>()));
|
|
||||||
auto json_config = json::parse(config_file);
|
|
||||||
json_config.at("Core").at("NumberOfConnectors") = this->r_evse_manager.size();
|
|
||||||
|
|
||||||
// 合并用户配置
|
|
||||||
if (fs::exists(user_config_path)) {
|
|
||||||
std::ifstream ifs(user_config_path.c_str());
|
|
||||||
std::string user_config_file((std::istreambuf_iterator<char>(ifs)), (std::istreambuf_iterator<char>()));
|
|
||||||
const auto user_config = json::parse(user_config_file);
|
|
||||||
json_config.merge_patch(user_config);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
这种方法允许系统管理员通过两个配置文件分别维护基本设置和用户定制,增强了配置的灵活性。
|
|
||||||
|
|
||||||
#### EVSE-连接器映射建立
|
|
||||||
|
|
||||||
OCPP需要维护EVerest内部EVSE/连接器ID与OCPP协议ID的映射关系
|
|
||||||
|
|
||||||
```c
|
|
||||||
void OCPP::init_evse_connector_map() {
|
|
||||||
int32_t ocpp_connector_id = 1; // OCPP连接器ID
|
|
||||||
int32_t evse_id = 1; // EVerest EVSE管理器ID
|
|
||||||
|
|
||||||
for (const auto& evse : this->r_evse_manager) {
|
|
||||||
const auto _evse = evse->call_get_evse();
|
|
||||||
std::map<int32_t, int32_t> connector_map; // 映射EVerest连接器ID到OCPP连接器ID
|
|
||||||
|
|
||||||
// 检查EVSE ID是否连续
|
|
||||||
if (_evse.id != evse_id) {
|
|
||||||
throw std::runtime_error("Configured evse_id(s) must be starting with 1 counting upwards");
|
|
||||||
}
|
|
||||||
|
|
||||||
// 处理每个连接器
|
|
||||||
for (const auto& connector : _evse.connectors) {
|
|
||||||
connector_map[connector.id] = ocpp_connector_id;
|
|
||||||
this->connector_evse_index_map[ocpp_connector_id] = evse_id - 1; // 索引对应r_evse_manager
|
|
||||||
ocpp_connector_id++;
|
|
||||||
}
|
|
||||||
|
|
||||||
// 处理没有显式连接器的EVSE
|
|
||||||
if (connector_map.size() == 0) {
|
|
||||||
this->connector_evse_index_map[ocpp_connector_id] = evse_id - 1;
|
|
||||||
connector_map[1] = ocpp_connector_id;
|
|
||||||
ocpp_connector_id++;
|
|
||||||
}
|
|
||||||
|
|
||||||
this->evse_connector_map[_evse.id] = connector_map;
|
|
||||||
evse_id++;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
这个映射是OCPP模块的核心数据结构之一,用于在OCPP连接器ID与EVerest内部ID之间转换,确保消息正确路由。
|
|
||||||
|
|
||||||
#### ChargePoint核心创建
|
|
||||||
|
|
||||||
在init方法结束时,模块创建了OCPP通信的核心组件
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
this->charge_point = std::make_unique<ocpp::v16::ChargePoint>(
|
|
||||||
json_config.dump(), // 配置JSON
|
|
||||||
this->ocpp_share_path, // 共享路径
|
|
||||||
user_config_path, // 用户配置路径
|
|
||||||
std::filesystem::path(this->config.DatabasePath), // 数据库路径
|
|
||||||
sql_init_path, // SQL初始化脚本路径
|
|
||||||
std::filesystem::path(this->config.MessageLogPath), // 消息日志路径
|
|
||||||
std::make_shared<EvseSecurity>(*this->r_security)); // 安全组件
|
|
||||||
```
|
|
||||||
|
|
||||||
这一步创建了处理所有OCPP通信的核心对象,并为其提供了:
|
|
||||||
|
|
||||||
- 配置数据
|
|
||||||
- 持久化存储位置
|
|
||||||
- 日志记录路径
|
|
||||||
- 安全接口
|
|
||||||
|
|
||||||
EvseSecurity是一个适配器类,将EVerest安全接口转换为OCPP库需要的接口格式。
|
|
||||||
|
|
||||||
#### 回调函数注册
|
|
||||||
|
|
||||||
在ready方法中,模块注册了多个回调函数,建立了OCPP事件与EVerest动作之间的桥梁
|
|
||||||
|
|
||||||
##### 充电控制回调
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// 暂停充电回调
|
|
||||||
this->charge_point->register_pause_charging_callback([this](int32_t connector) {
|
|
||||||
if (this->connector_evse_index_map.count(connector)) {
|
|
||||||
return this->r_evse_manager.at(this->connector_evse_index_map.at(connector))->call_pause_charging();
|
|
||||||
} else {
|
|
||||||
return false;
|
|
||||||
}
|
|
||||||
});
|
|
||||||
|
|
||||||
// 恢复充电回调
|
|
||||||
this->charge_point->register_resume_charging_callback([this](int32_t connector) {
|
|
||||||
if (this->connector_evse_index_map.count(connector)) {
|
|
||||||
return this->r_evse_manager.at(this->connector_evse_index_map.at(connector))->call_resume_charging();
|
|
||||||
} else {
|
|
||||||
return false;
|
|
||||||
}
|
|
||||||
});
|
|
||||||
|
|
||||||
// 停止交易回调
|
|
||||||
this->charge_point->register_stop_transaction_callback([this](int32_t connector, ocpp::v16::Reason reason) {
|
|
||||||
if (this->connector_evse_index_map.count(connector)) {
|
|
||||||
types::evse_manager::StopTransactionRequest req;
|
|
||||||
req.reason = types::evse_manager::string_to_stop_transaction_reason(
|
|
||||||
ocpp::v16::conversions::reason_to_string(reason));
|
|
||||||
return this->r_evse_manager.at(this->connector_evse_index_map.at(connector))->call_stop_transaction(req);
|
|
||||||
} else {
|
|
||||||
return false;
|
|
||||||
}
|
|
||||||
});
|
|
||||||
```
|
|
||||||
|
|
||||||
### OCPP消息处理流程
|
|
||||||
|
|
||||||
#### 接收消息
|
|
||||||
|
|
||||||
WebSocket接收CSMS消息
|
|
||||||
JSON解析为OCPP对象
|
|
||||||
|
|
||||||
#### 消息分发
|
|
||||||
|
|
||||||
根据消息类型调用对应处理函数
|
|
||||||
执行业务逻辑
|
|
||||||
|
|
||||||
#### 响应生成
|
|
||||||
|
|
||||||
创建响应对象
|
|
||||||
序列化为JSON
|
|
||||||
通过WebSocket发送
|
|
||||||
|
|
||||||
#### 状态更新
|
|
||||||
|
|
||||||
更新内部状态
|
|
||||||
发布相关事件
|
|
||||||
|
|
||||||
### 认证流程
|
|
||||||
|
|
||||||
1. 接收认证令牌
|
|
||||||
2. 发送Authorize.req消息到CSMS
|
|
||||||
3. 接收Authorize.conf响应
|
|
||||||
4. 转换OCPP认证状态为EVerest认证状态
|
|
||||||
5. 返回认证结果
|
|
||||||
|
|
||||||
### 充电计划处理
|
|
||||||
|
|
||||||
1. 定时器触发
|
|
||||||
2. 请求最新充电计划
|
|
||||||
3. 转换为EVerest格式
|
|
||||||
4. 发布到MQTT
|
|
||||||
5. 传递给能源限制接口
|
|
||||||
|
|
||||||
## 与其他模块交互
|
|
||||||
|
|
||||||
### EVSE管理器交互
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// 伪代码
|
|
||||||
void handle_evse_status_change(int32_t evse_id, evse_manager::EVSEState state) {
|
|
||||||
// 转换状态
|
|
||||||
ocpp::v16::ChargePointStatus cp_status = convert_evse_state(state);
|
|
||||||
|
|
||||||
// 向CSMS发送状态变更
|
|
||||||
charge_point->status_notification(evse_id, cp_status);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### 安全模块交互
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// 初始化安全组件
|
|
||||||
auto evse_security = std::make_shared<EvseSecurity>(*r_security);
|
|
||||||
|
|
||||||
// 配置ChargePoint使用安全组件
|
|
||||||
charge_point_config.evse_security = evse_security;
|
|
||||||
```
|
|
||||||
|
|
||||||
### OCPPExtensionExample扩展
|
|
||||||
|
|
||||||
通过OCPPExtensionExample模式,可以扩展OCPP功能:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
class OCPPExtensionExample : public Everest::ModuleBase {
|
|
||||||
public:
|
|
||||||
OCPPExtensionExample(const ModuleInfo& info,
|
|
||||||
std::unique_ptr<emptyImplBase> p_empty,
|
|
||||||
std::unique_ptr<ocpp_1_6_charge_pointIntf> r_ocpp,
|
|
||||||
Conf& config);
|
|
||||||
|
|
||||||
void ready() {
|
|
||||||
// 监控配置变更
|
|
||||||
std::vector<std::string> keys_to_monitor = parse_keys(config.keys_to_monitor);
|
|
||||||
r_ocpp->monitor_configuration_keys(keys_to_monitor);
|
|
||||||
|
|
||||||
// 订阅变更通知
|
|
||||||
r_ocpp->subscribe_configuration_key([this](types::ocpp::KeyValue key_value) {
|
|
||||||
// 处理配置变更
|
|
||||||
});
|
|
||||||
}
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
# OCPP 2.0.1
|
|
||||||
|
|
||||||
todo
|
|
||||||
@ -1,625 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2025-03-05 10:35
|
|
||||||
updated: 2025-03-11 14:46
|
|
||||||
tags:
|
|
||||||
- Everest
|
|
||||||
- ocpp
|
|
||||||
link: false
|
|
||||||
share: true
|
|
||||||
publish: true
|
|
||||||
---
|
|
||||||
|
|
||||||
# 项目概述
|
|
||||||
|
|
||||||
EVerest-Framework 是一个支持多语言模块化开发的框架,主要用于电动汽车充电基础设施的开发。从代码中可以看出,它支持 C++、JavaScript、Rust 和 Python 编程语言的模块。
|
|
||||||
|
|
||||||
# 项目结构
|
|
||||||
|
|
||||||
```sh
|
|
||||||
EVerest-Framework/
|
|
||||||
│
|
|
||||||
├── cmake/ # CMake 模块和辅助函数
|
|
||||||
│ ├── NodeApiVersion.cmake
|
|
||||||
│ └── find-mqttc.cmake
|
|
||||||
│
|
|
||||||
├── everestjs/ # JavaScript 模块支持
|
|
||||||
│ ├── CMakeLists.txt
|
|
||||||
│ ├── conversions.cpp
|
|
||||||
│ └── ...
|
|
||||||
│
|
|
||||||
├── everestpy/ # Python 模块支持
|
|
||||||
│ ├── CMakeLists.txt
|
|
||||||
│ ├── setup.cfg
|
|
||||||
│ └── src/
|
|
||||||
│ └── everest/
|
|
||||||
│
|
|
||||||
├── everestrs/ # Rust 模块支持(可选)
|
|
||||||
│ └── everestrs_sys/
|
|
||||||
│
|
|
||||||
├── include/ # 头文件
|
|
||||||
│ ├── compile_time_settings.hpp.in
|
|
||||||
│ └── ...
|
|
||||||
│
|
|
||||||
├── lib/ # 核心库实现
|
|
||||||
│ ├── config.cpp # 配置系统实现
|
|
||||||
│ └── ...
|
|
||||||
│
|
|
||||||
├── schemas/ # JSON Schema 定义
|
|
||||||
│ ├── config.yaml
|
|
||||||
│ ├── manifest.yaml
|
|
||||||
│ ├── interface.yaml
|
|
||||||
│ └── ...
|
|
||||||
│
|
|
||||||
├── src/ # 源代码
|
|
||||||
│ ├── manager.cpp # 主管理器实现
|
|
||||||
│ ├── controller/
|
|
||||||
│ └── ...
|
|
||||||
│
|
|
||||||
└── tests/ # 测试代码
|
|
||||||
├── CMakeLists.txt
|
|
||||||
├── test_config.cpp
|
|
||||||
├── test_configs/
|
|
||||||
├── test_modules/
|
|
||||||
└── test_interfaces/
|
|
||||||
```
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
graph LR
|
|
||||||
A[everest-framework] --> B[src]
|
|
||||||
A --> C[tests]
|
|
||||||
A --> D[schemas]
|
|
||||||
|
|
||||||
B --> B1[manager.cpp]
|
|
||||||
B --> B2[其他源文件]
|
|
||||||
|
|
||||||
C --> C1[test_config.cpp]
|
|
||||||
C --> C2[test_configs]
|
|
||||||
C --> C3[test_modules]
|
|
||||||
C --> C4[test_interfaces]
|
|
||||||
|
|
||||||
C2 --> C21[valid_config.yaml]
|
|
||||||
C2 --> C22[broken_config.yaml]
|
|
||||||
C2 --> C23[missing_module_config.yaml]
|
|
||||||
C2 --> C24[broken_manifest_config.yaml]
|
|
||||||
C2 --> C25[broken_manifest2_config.yaml]
|
|
||||||
C2 --> C26[valid_manifest_missing_interface_config.yaml]
|
|
||||||
```
|
|
||||||
|
|
||||||
# 核心组件
|
|
||||||
|
|
||||||
## 模块系统
|
|
||||||
|
|
||||||
从代码中可以看出,EVerest 框架支持多种语言的模块
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
classDiagram
|
|
||||||
class ModuleStartInfo {
|
|
||||||
+string name
|
|
||||||
+string printable_name
|
|
||||||
+Language language
|
|
||||||
+fs::path path
|
|
||||||
}
|
|
||||||
|
|
||||||
class Language {
|
|
||||||
<<enumeration>>
|
|
||||||
cpp
|
|
||||||
javascript
|
|
||||||
python
|
|
||||||
rust
|
|
||||||
}
|
|
||||||
|
|
||||||
ModuleStartInfo --> Language
|
|
||||||
```
|
|
||||||
|
|
||||||
## 配置系统
|
|
||||||
|
|
||||||
EVerest-Framework 的配置系统主要由 Config 类实现,负责加载、验证和处理配置文件,以及管理模块之间的依赖关系。配置系统使用 YAML 格式的配置文件来描述系统中的模块、它们的配置参数以及模块之间的连接关系。
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
graph TD
|
|
||||||
A[Config] --> B[active_modules]
|
|
||||||
B --> C[模块1]
|
|
||||||
B --> D[模块2]
|
|
||||||
C --> C1[module: 模块名称]
|
|
||||||
D --> D1[module: 模块名称]
|
|
||||||
```
|
|
||||||
|
|
||||||
### 配置系统工作流程
|
|
||||||
|
|
||||||
#### 配置文件加载
|
|
||||||
|
|
||||||
配置系统首先从指定路径加载主配置文件(通常是 config.yaml ):
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// 在 Config 构造函数中加载配置文件
|
|
||||||
fs::path config_path = rs->config_file;
|
|
||||||
try {
|
|
||||||
if (manager) {
|
|
||||||
EVLOG_info << fmt::format("Loading config file at: {}", fs::canonical(config_path).string());
|
|
||||||
}
|
|
||||||
auto complete_config = load_yaml(config_path);
|
|
||||||
|
|
||||||
// 尝试加载用户配置(如果存在)
|
|
||||||
auto user_config_path = config_path.parent_path() / "user-config" / config_path.filename();
|
|
||||||
if (fs::exists(user_config_path)) {
|
|
||||||
// 加载用户配置并合并到主配置
|
|
||||||
auto user_config = load_yaml(user_config_path);
|
|
||||||
complete_config.merge_patch(user_config);
|
|
||||||
}
|
|
||||||
|
|
||||||
// 其他处理...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 配置验证
|
|
||||||
|
|
||||||
加载配置后,系统会使用 JSON Schema 验证配置的有效性:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
json_validator validator(Config::loader, Config::format_checker);
|
|
||||||
validator.set_root_schema(this->_schemas.config);
|
|
||||||
auto patch = validator.validate(complete_config);
|
|
||||||
if (!patch.is_null()) {
|
|
||||||
// 使用默认值扩展配置
|
|
||||||
complete_config = complete_config.patch(patch);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 类型和接口加载
|
|
||||||
|
|
||||||
配置系统还会加载类型定义和接口定义文件
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// 加载类型文件
|
|
||||||
for (auto const& types_entry : fs::recursive_directory_iterator(this->rs->types_dir)) {
|
|
||||||
// 处理每个类型文件...
|
|
||||||
}
|
|
||||||
|
|
||||||
// 加载接口文件(在其他地方实现)
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 模块依赖解析
|
|
||||||
|
|
||||||
一个关键功能是解析模块之间的依赖关系,通过 resolve_all_requirements 方法实现:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
void Config::resolve_all_requirements() {
|
|
||||||
// 遍历所有模块
|
|
||||||
for (auto& element : this->main.items()) {
|
|
||||||
const auto& module_id = element.key();
|
|
||||||
auto& module_config = element.value();
|
|
||||||
|
|
||||||
// 检查模块的需求是否在清单中定义
|
|
||||||
// ...
|
|
||||||
|
|
||||||
// 解析每个需求
|
|
||||||
for (auto& element : this->manifests[module_config["module"].get<std::string>()]["requires"].items()) {
|
|
||||||
const auto& requirement_id = element.key();
|
|
||||||
auto& requirement = element.value();
|
|
||||||
|
|
||||||
// 检查需求是否满足
|
|
||||||
// ...
|
|
||||||
|
|
||||||
// 检查连接数量是否符合要求
|
|
||||||
// ...
|
|
||||||
|
|
||||||
// 验证每个连接
|
|
||||||
for (uint64_t connection_num = 0; connection_num < connections.size(); connection_num++) {
|
|
||||||
// 验证连接的模块是否存在
|
|
||||||
// 验证接口是否匹配
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 配置访问
|
|
||||||
|
|
||||||
配置系统提供了多种方法来访问配置数据:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// 获取模块配置
|
|
||||||
ModuleConfigs Config::get_module_configs(const std::string& module_id) {
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
|
|
||||||
// 解析模块需求
|
|
||||||
json Config::resolve_requirement(const std::string& module_id, const std::string& requirement_id) {
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
|
|
||||||
// 获取接口定义
|
|
||||||
json Config::get_interface_definition(const std::string& interface_name) {
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### 配置文件结构
|
|
||||||
|
|
||||||
EVerest 的主配置文件结构如下:
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
active_modules:
|
|
||||||
module_id_1:
|
|
||||||
module: "ModuleName1"
|
|
||||||
config_maps:
|
|
||||||
!module: { /* 模块级配置 */ }
|
|
||||||
implementation_id_1: { /* 实现级配置 */ }
|
|
||||||
connections:
|
|
||||||
requirement_id_1:
|
|
||||||
- module_id: "module_id_2"
|
|
||||||
implementation_id: "implementation_id_2"
|
|
||||||
|
|
||||||
module_id_2:
|
|
||||||
# 类似结构...
|
|
||||||
```
|
|
||||||
|
|
||||||
### 配置系统与模块执行
|
|
||||||
|
|
||||||
配置系统与模块执行紧密相关。在 manager.cpp 中,系统根据配置启动相应的模块:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
// 根据模块语言类型执行不同的启动逻辑
|
|
||||||
static SubprocessHandle exec_cpp_module(const ModuleStartInfo& module_info, std::shared_ptr<RuntimeSettings> rs) {
|
|
||||||
// 启动 C++ 模块...
|
|
||||||
}
|
|
||||||
|
|
||||||
static SubprocessHandle exec_javascript_module(const ModuleStartInfo& module_info, std::shared_ptr<RuntimeSettings> rs) {
|
|
||||||
// 启动 JavaScript 模块...
|
|
||||||
}
|
|
||||||
|
|
||||||
// 还有 Python 和 Rust 模块的启动逻辑...
|
|
||||||
```
|
|
||||||
|
|
||||||
### 多语言支持
|
|
||||||
|
|
||||||
EVerest-Framework 支持多种编程语言的模块,通过特定的包装器实现:
|
|
||||||
|
|
||||||
1. C++ 模块直接使用框架库
|
|
||||||
2. JavaScript 模块通过 everestjs 包装器
|
|
||||||
3. Python 模块通过 everestpy 包装器
|
|
||||||
4. Rust 模块通过 everestrs 包装器(可选功能)
|
|
||||||
|
|
||||||
每种语言的包装器都提供了访问配置系统的接口,例如 Python 的 ModuleSetup 类:
|
|
||||||
|
|
||||||
```py
|
|
||||||
class ModuleSetup:
|
|
||||||
@property
|
|
||||||
def configs(self) -> ModuleSetupConfigurations: ...
|
|
||||||
|
|
||||||
@property
|
|
||||||
def connections(self) -> dict[str, list[Fulfillment]]: ...
|
|
||||||
```
|
|
||||||
|
|
||||||
### 总结
|
|
||||||
|
|
||||||
EVerest-Framework 的配置系统是一个复杂而强大的系统,它通过以下步骤工作:
|
|
||||||
|
|
||||||
1. 加载并验证 YAML 格式的配置文件
|
|
||||||
2. 加载类型定义和接口定义
|
|
||||||
3. 解析模块之间的依赖关系
|
|
||||||
4. 验证模块连接的有效性
|
|
||||||
5. 提供配置数据访问接口
|
|
||||||
6. 根据配置启动相应的模块
|
|
||||||
|
|
||||||
这种设计使得 EVerest 能够支持模块化、多语言的开发方式,同时确保模块之间的依赖关系正确无误。
|
|
||||||
|
|
||||||
## 模块执行机制
|
|
||||||
|
|
||||||
EVerest-Framework 是一个支持多语言模块化开发的框架,它通过配置文件定义模块及其依赖关系,然后启动并管理这些模块。
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
graph TD
|
|
||||||
A[配置加载] --> B[配置验证]
|
|
||||||
B --> C[模块依赖解析]
|
|
||||||
C --> D[模块启动]
|
|
||||||
D --> E1[C++模块执行]
|
|
||||||
D --> E2[JavaScript模块执行]
|
|
||||||
D --> E3[Python模块执行]
|
|
||||||
D --> E4[Rust模块执行]
|
|
||||||
E1 --> F[模块间通信]
|
|
||||||
E2 --> F
|
|
||||||
E3 --> F
|
|
||||||
E4 --> F
|
|
||||||
```
|
|
||||||
|
|
||||||
### 模块执行流程图
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
sequenceDiagram
|
|
||||||
participant Manager as 管理器
|
|
||||||
participant Config as 配置系统
|
|
||||||
participant MQTT as MQTT抽象层
|
|
||||||
participant Module as 模块进程
|
|
||||||
|
|
||||||
Manager->>Config: 加载配置文件
|
|
||||||
Config->>Config: 验证配置
|
|
||||||
Config->>Config: 加载模块清单
|
|
||||||
Config->>Config: 解析模块依赖
|
|
||||||
Manager->>Manager: 准备模块启动信息
|
|
||||||
|
|
||||||
loop 对每个模块
|
|
||||||
Manager->>Module: 创建子进程
|
|
||||||
alt C++模块
|
|
||||||
Manager->>Module: exec_cpp_module()
|
|
||||||
else JavaScript模块
|
|
||||||
Manager->>Module: exec_javascript_module()
|
|
||||||
else Python模块
|
|
||||||
Manager->>Module: exec_python_module()
|
|
||||||
end
|
|
||||||
Module->>MQTT: 连接MQTT代理
|
|
||||||
Module->>Config: 获取模块配置
|
|
||||||
Module->>Module: 初始化模块
|
|
||||||
Module->>Manager: 报告就绪状态
|
|
||||||
end
|
|
||||||
|
|
||||||
Manager->>Manager: 监控模块运
|
|
||||||
```
|
|
||||||
|
|
||||||
### 模块启动流程
|
|
||||||
|
|
||||||
从代码中可以看出,模块启动主要由 `start_modules` 和 `spawn_modules` 函数处理:
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
sequenceDiagram
|
|
||||||
participant Manager
|
|
||||||
participant Config
|
|
||||||
participant ModuleStartInfo
|
|
||||||
participant SubprocessHandle
|
|
||||||
|
|
||||||
Manager->>Config: get_main_config()
|
|
||||||
Config-->>Manager: 返回配置信息
|
|
||||||
loop 遍历每个模块
|
|
||||||
Manager->>ModuleStartInfo: 创建模块启动信息
|
|
||||||
Manager->>+SubprocessHandle: spawn_modules()
|
|
||||||
SubprocessHandle->>SubprocessHandle: 根据语言类型选择执行方式
|
|
||||||
SubprocessHandle-->>-Manager: 返回进程句柄
|
|
||||||
end
|
|
||||||
```
|
|
||||||
|
|
||||||
### 模块执行代码分析
|
|
||||||
|
|
||||||
#### 模块启动信息准备
|
|
||||||
|
|
||||||
首先,系统会从配置中获取所有需要启动的模块信息:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
static std::map<pid_t, std::string> start_modules(Config& config, MQTTAbstraction& mqtt_abstraction,
|
|
||||||
const std::vector<std::string>& ignored_modules,
|
|
||||||
const std::vector<std::string>& standalone_modules,
|
|
||||||
std::shared_ptr<RuntimeSettings> rs, StatusFifo& status_fifo,
|
|
||||||
error::ErrorManager& err_manager) {
|
|
||||||
// ...
|
|
||||||
auto main_config = config.get_main_config();
|
|
||||||
modules_to_spawn.reserve(main_config.size());
|
|
||||||
|
|
||||||
for (const auto& module : main_config.items()) {
|
|
||||||
std::string module_name = module.key();
|
|
||||||
// ... 准备模块启动信息
|
|
||||||
}
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 模块执行函数
|
|
||||||
|
|
||||||
系统根据模块的语言类型选择不同的执行方式:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
static std::map<pid_t, std::string> spawn_modules(const std::vector<ModuleStartInfo>& modules,
|
|
||||||
std::shared_ptr<RuntimeSettings> rs) {
|
|
||||||
std::map<pid_t, std::string> started_modules;
|
|
||||||
|
|
||||||
for (const auto& module : modules) {
|
|
||||||
auto handle = [&module, &rs]() -> SubprocessHandle {
|
|
||||||
switch (module.language) {
|
|
||||||
case ModuleStartInfo::Language::cpp:
|
|
||||||
return exec_cpp_module(module, rs);
|
|
||||||
case ModuleStartInfo::Language::javascript:
|
|
||||||
return exec_javascript_module(module, rs);
|
|
||||||
case ModuleStartInfo::Language::python:
|
|
||||||
return exec_python_module(module, rs);
|
|
||||||
default:
|
|
||||||
throw std::logic_error("Module language not in enum");
|
|
||||||
}
|
|
||||||
}();
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 不同语言模块的执行
|
|
||||||
|
|
||||||
##### C++ 模块执行
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
static SubprocessHandle exec_cpp_module(const ModuleStartInfo& module_info, std::shared_ptr<RuntimeSettings> rs) {
|
|
||||||
const auto exec_binary = module_info.path.c_str();
|
|
||||||
std::vector<std::string> arguments = {module_info.printable_name, "--prefix", rs->prefix.string(), "--conf",
|
|
||||||
rs->config_file.string(), "--module", module_info.name};
|
|
||||||
|
|
||||||
auto handle = create_subprocess();
|
|
||||||
if (handle.is_child()) {
|
|
||||||
auto argv_list = arguments_to_exec_argv(arguments);
|
|
||||||
execv(exec_binary, argv_list.data());
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
return handle;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
##### JavaScript 模块执行
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
static SubprocessHandle exec_javascript_module(const ModuleStartInfo& module_info,
|
|
||||||
std::shared_ptr<RuntimeSettings> rs) {
|
|
||||||
// 设置环境变量
|
|
||||||
const auto node_modules_path = rs->prefix / defaults::LIB_DIR / defaults::NAMESPACE / "node_modules";
|
|
||||||
setenv("NODE_PATH", node_modules_path.c_str(), 0);
|
|
||||||
setenv("EV_MODULE", module_info.name.c_str(), 1);
|
|
||||||
setenv("EV_PREFIX", rs->prefix.c_str(), 0);
|
|
||||||
setenv("EV_CONF_FILE", rs->config_file.c_str(), 0);
|
|
||||||
// ...
|
|
||||||
|
|
||||||
const auto node_binary = "node";
|
|
||||||
std::vector<std::string> arguments = {
|
|
||||||
"node",
|
|
||||||
"--unhandled-rejections=strict",
|
|
||||||
module_info.path.string(),
|
|
||||||
};
|
|
||||||
|
|
||||||
auto handle = create_subprocess();
|
|
||||||
if (handle.is_child()) {
|
|
||||||
auto argv_list = arguments_to_exec_argv(arguments);
|
|
||||||
execvp(node_binary, argv_list.data());
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
return handle;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
##### Python 模块执行
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
static SubprocessHandle exec_python_module(const ModuleStartInfo& module_info, std::shared_ptr<RuntimeSettings> rs) {
|
|
||||||
// 设置环境变量
|
|
||||||
const auto pythonpath = rs->prefix / defaults::LIB_DIR / defaults::NAMESPACE / "everestpy";
|
|
||||||
|
|
||||||
setenv("EV_MODULE", module_info.name.c_str(), 1);
|
|
||||||
setenv("EV_PREFIX", rs->prefix.c_str(), 0);
|
|
||||||
setenv("EV_CONF_FILE", rs->config_file.c_str(), 0);
|
|
||||||
setenv("PYTHONPATH", pythonpath.c_str(), 0);
|
|
||||||
// ...
|
|
||||||
|
|
||||||
const auto python_binary = "python3";
|
|
||||||
std::vector<std::string> arguments = {python_binary, module_info.path.c_str()};
|
|
||||||
|
|
||||||
auto handle = create_subprocess();
|
|
||||||
if (handle.is_child()) {
|
|
||||||
auto argv_list = arguments_to_exec_argv(arguments);
|
|
||||||
execvp(python_binary, argv_list.data());
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
return handle;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### 模块初始化和通信
|
|
||||||
|
|
||||||
模块启动后,会进行初始化并与其他模块通信:
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
graph LR
|
|
||||||
A[模块启动] --> B[创建模块实例]
|
|
||||||
B --> C[say_hello 获取模块设置]
|
|
||||||
C --> D[实现命令处理器]
|
|
||||||
D --> E[init_done 信号准备就绪]
|
|
||||||
E --> F[模块间通信]
|
|
||||||
```
|
|
||||||
|
|
||||||
#### Python 模块示例
|
|
||||||
|
|
||||||
Python 模块的初始化和通信流程:
|
|
||||||
|
|
||||||
```py
|
|
||||||
class Module:
|
|
||||||
def __init__(self, module_id: str, session: RuntimeSession) -> None:
|
|
||||||
# 初始化模块
|
|
||||||
pass
|
|
||||||
|
|
||||||
def say_hello(self) -> ModuleSetup:
|
|
||||||
# 获取模块设置信息
|
|
||||||
pass
|
|
||||||
|
|
||||||
def implement_command(self, implementation_id: str, command_name: str,
|
|
||||||
handler: Callable[[dict], dict]) -> None:
|
|
||||||
# 实现命令处理器
|
|
||||||
pass
|
|
||||||
|
|
||||||
def init_done(self) -> None:
|
|
||||||
# 信号模块准备就绪
|
|
||||||
pass
|
|
||||||
|
|
||||||
def call_command(self, fulfillment: Fulfillment,
|
|
||||||
command_name: str, args: dict) -> None:
|
|
||||||
# 调用其他模块的命令
|
|
||||||
pass
|
|
||||||
```
|
|
||||||
|
|
||||||
### 模块间依赖和通信
|
|
||||||
|
|
||||||
模块间的依赖关系通过配置文件中的 connections 部分定义:
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
graph LR
|
|
||||||
A[模块A] -->|需求1| B[模块B]
|
|
||||||
A -->|需求2| C[模块C]
|
|
||||||
D[模块D] -->|需求3| A
|
|
||||||
```
|
|
||||||
|
|
||||||
在代码中,这些依赖关系通过 `resolve_requirement` 函数解析:
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
json Config::resolve_requirement(const std::string& module_id, const std::string& requirement_id) {
|
|
||||||
// 检查模块是否存在
|
|
||||||
auto module_name_it = this->module_names.find(module_id);
|
|
||||||
if (module_name_it == this->module_names.end()) {
|
|
||||||
EVLOG_AND_THROW(EverestApiError(fmt::format("Requested requirement id '{}' of module {} not found in config!",
|
|
||||||
requirement_id, printable_identifier(module_id))));
|
|
||||||
}
|
|
||||||
|
|
||||||
// 检查连接是否存在
|
|
||||||
auto& module_config = this->main[module_id];
|
|
||||||
std::string module_name = module_name_it->second;
|
|
||||||
auto& requirement = this->manifests[module_name]["requires"][requirement_id];
|
|
||||||
if (!module_config["connections"].contains(requirement_id)) {
|
|
||||||
return json::array(); // 如果配置中没有此需求的连接,返回空数组
|
|
||||||
}
|
|
||||||
|
|
||||||
// 根据连接数量返回不同格式
|
|
||||||
if (requirement["min_connections"] == 1 && requirement["max_connections"] == 1) {
|
|
||||||
return module_config["connections"][requirement_id].at(0);
|
|
||||||
}
|
|
||||||
return module_config["connections"][requirement_id];
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### 总结
|
|
||||||
|
|
||||||
EVerest-Framework 的模块执行流程包括以下几个关键步骤:
|
|
||||||
|
|
||||||
1. 加载和验证配置文件
|
|
||||||
2. 解析模块依赖关系
|
|
||||||
3. 准备模块启动信息
|
|
||||||
4. 根据模块语言类型选择执行方式
|
|
||||||
5. 创建子进程执行模块
|
|
||||||
6. 模块初始化并建立通信
|
|
||||||
|
|
||||||
这种设计使得 EVerest 能够支持多语言模块化开发,并通过配置文件灵活地定义模块间的依赖关系。
|
|
||||||
|
|
||||||
# 测试系统
|
|
||||||
|
|
||||||
项目使用 Catch2 测试框架进行单元测试,主要测试配置解析功能:
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
graph LR
|
|
||||||
A[test_config.cpp] --> B[测试空配置]
|
|
||||||
A --> C[测试无效主目录]
|
|
||||||
A --> D[测试不存在的配置文件]
|
|
||||||
A --> E[测试损坏的配置文件]
|
|
||||||
A --> F[测试引用不存在模块的配置]
|
|
||||||
A --> G[测试使用损坏清单的模块]
|
|
||||||
A --> H[测试有效清单但引用无效接口]
|
|
||||||
A --> I[测试有效配置]
|
|
||||||
```
|
|
||||||
|
|
||||||
# 项目依赖
|
|
||||||
|
|
||||||
项目依赖了一些第三方库:
|
|
||||||
|
|
||||||
- CodeCoverage.cmake (用于代码覆盖率测试)
|
|
||||||
- 元编程宏库 (来自 libextobjc)
|
|
||||||
- [[./EVerest-timer|EVerest-timer]]
|
|
||||||
- EVerest-log
|
|
||||||
@ -1,244 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2025-03-05 15:51
|
|
||||||
updated: 2025-03-11 11:42
|
|
||||||
tags:
|
|
||||||
- Everest
|
|
||||||
- ocpp
|
|
||||||
publish: true
|
|
||||||
link:
|
|
||||||
share: "true"
|
|
||||||
---
|
|
||||||
|
|
||||||
# 项目概述
|
|
||||||
|
|
||||||
libtimer 是 EVerest 项目的一个组件,主要==提供定时器功能==。EVerest 是一个开源的电动汽车充电站操作系统。libtimer 是一个相对独立的库,主要目的是为了支持==日志文件回放==功能:
|
|
||||||
|
|
||||||
```md
|
|
||||||
C++ timer library for the EVerest framework
|
|
||||||
===========================================
|
|
||||||
EVerest is aiming to enable logfile replay. All EVerest components have to utilize this library for time (and delay) related things in order to enable accelerated logfile replay speed in the future.
|
|
||||||
|
|
||||||
All documentation and the issue tracking can be found in our main repository here: https://github.com/EVerest/everest
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
# libtimer 测试代码分析
|
|
||||||
|
|
||||||
从测试代码 <mcfile name="libtimer_unit_test.cpp" path="d:\Code\github\EVerest\libtimer\tests\libtimer_unit_test.cpp"></mcfile> 中,可以看到:
|
|
||||||
|
|
||||||
1. 该库使用 Google Test 框架进行单元测试
|
|
||||||
2. 测试类 `LibTimerUnitTest` 继承自 `::testing::Test`
|
|
||||||
3. 包含标准的 `SetUp` 和 `TearDown` 方法
|
|
||||||
4. 目前只有一个简单的示例测试用例 `just_an_example`
|
|
||||||
|
|
||||||
# 与 everest-framework 的集成
|
|
||||||
|
|
||||||
从 [[./EVerest-framework|EVerest-framework]] 的 `Cmakelists.txt` 中,我们可以看到 libtimer 与 EVerest-framework 的关系:
|
|
||||||
|
|
||||||
1. EVerest-framework 依赖于 EVerest-timer(即 libtimer)
|
|
||||||
2. 在 CMake 配置中,EVerest-framework 将 EVerest-timer 作为必需的依赖项
|
|
||||||
3. 在打包时,EVerest-framework 会包含对 EVerest-timer 的依赖声明
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
graph LR
|
|
||||||
framework[everest-framework] --> timer[everest-timer/libtimer]
|
|
||||||
framework --> log[everest-log]
|
|
||||||
framework --> json[nlohmann_json]
|
|
||||||
framework --> schema[nlohmann_json_schema_validator]
|
|
||||||
framework --> fmt[fmt库]
|
|
||||||
framework --> date[date库]
|
|
||||||
```
|
|
||||||
|
|
||||||
# libtimer 功能
|
|
||||||
|
|
||||||
libtimer 是一个接口库(interface library),是一个纯头文件库(header-only library),实现代码都在头文件 `timer.hpp` 中。这种设计方式在C++中很常见,特别是对于模板库来说,因为**模板必须在编译时可见**。
|
|
||||||
|
|
||||||
## `timer.hpp`
|
|
||||||
|
|
||||||
这是一个基于3.4C++模板的计时器类,默认使用`date::utc_clock`作为时钟类型:
|
|
||||||
|
|
||||||
```16:17:libtimer/include/everest/timer.hpp
|
|
||||||
// template <typename TimerClock = date::steady_clock> class Timer {
|
|
||||||
template <typename TimerClock = date::utc_clock> class Timer {
|
|
||||||
```
|
|
||||||
|
|
||||||
### 主要成员变量
|
|
||||||
|
|
||||||
- `timer`: ASIO的定时器对象
|
|
||||||
- `callback`: 用户定义的回调函数
|
|
||||||
- `callback_wrapper`: 用于 interval 模式的包装回调函数
|
|
||||||
- `io_context`: boost::asio的IO上下文
|
|
||||||
- `timer_thread`: 定时器线程指针
|
|
||||||
|
|
||||||
### 构造函数
|
|
||||||
|
|
||||||
类提供了四个构造函数:
|
|
||||||
|
|
||||||
- 默认构造函数:创建自己的 io_context 和线程
|
|
||||||
- 带回调函数的构造函数:创建自己的 io_context 和线程
|
|
||||||
- 使用外部 io_context 的构造函数
|
|
||||||
- 使用外部 io_context 和回调函数的构造函数
|
|
||||||
|
|
||||||
### 主要功能方法
|
|
||||||
|
|
||||||
- `at()`: 在指定时间点执行回调
|
|
||||||
- `interval()`: 按指定时间间隔周期性执行回调
|
|
||||||
- `timeout()`: 在指定延时后执行一次回调
|
|
||||||
- `stop()`: 停止定时器
|
|
||||||
|
|
||||||
### 别名
|
|
||||||
|
|
||||||
类提供了两个别名:
|
|
||||||
|
|
||||||
```180:181:libtimer/include/everest/timer.hpp
|
|
||||||
using SteadyTimer = Timer<date::utc_clock>;
|
|
||||||
using SystemTimer = Timer<date::utc_clock>;
|
|
||||||
```
|
|
||||||
|
|
||||||
### 主要特点
|
|
||||||
|
|
||||||
1. 基于boost::asio实现,支持异步操作
|
|
||||||
2. 支持自管理和外部管理两种IO上下文模式
|
|
||||||
3. 提供了精确的时间控制功能
|
|
||||||
4. 线程安全设计
|
|
||||||
5. 支持多种时间点和时间间隔的表示方式
|
|
||||||
6. 可以方便地用于日志回放功能,这也是该库的主要目的
|
|
||||||
|
|
||||||
使用示例可以参考examples/main.cpp,其中展示了如何使用at、interval和timeout等功能。这个库的设计非常灵活,既可以独立使用,也可以集成到使用boost::asio的更大系统中。
|
|
||||||
|
|
||||||
### 代码解读
|
|
||||||
|
|
||||||
以`at`函数为例:
|
|
||||||
|
|
||||||
```c
|
|
||||||
/// Executes the given callback at the given timepoint
|
|
||||||
template <class Clock, class Duration = typename Clock::duration>
|
|
||||||
void at(const std::function<void()>& callback, const std::chrono::time_point<Clock, Duration>& time_point) {
|
|
||||||
this->stop();
|
|
||||||
|
|
||||||
this->callback = callback;
|
|
||||||
|
|
||||||
this->at(time_point);
|
|
||||||
}
|
|
||||||
|
|
||||||
/// Executes the at the given timepoint
|
|
||||||
template <class Clock, class Duration = typename Clock::duration>
|
|
||||||
void at(const std::chrono::time_point<Clock, Duration>& time_point) {
|
|
||||||
this->stop();
|
|
||||||
|
|
||||||
if (this->callback == nullptr) {
|
|
||||||
return;
|
|
||||||
}
|
|
||||||
|
|
||||||
if (this->timer != nullptr) {
|
|
||||||
// use asio timer
|
|
||||||
this->timer->expires_at(time_point);
|
|
||||||
this->timer->async_wait([this](const boost::system::error_code& e) {
|
|
||||||
if (e) {
|
|
||||||
return;
|
|
||||||
}
|
|
||||||
|
|
||||||
this->callback();
|
|
||||||
});
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
这段代码定义了一个定时器类中的两个 at() 方法,用于在指定的时间点执行回调函数。
|
|
||||||
|
|
||||||
```c
|
|
||||||
template <class Clock, class Duration = typename Clock::duration>
|
|
||||||
```
|
|
||||||
|
|
||||||
这一行声明了一个模板函数,**可以接受不同类型的时钟和时间间隔**。
|
|
||||||
|
|
||||||
```cpp
|
|
||||||
void at(const std::function<void()>& callback,
|
|
||||||
const std::chrono::time_point<Clock, Duration>& time_point )
|
|
||||||
```
|
|
||||||
|
|
||||||
第一个参数 `const std::function<void()>& callback:`
|
|
||||||
|
|
||||||
- `std::function<void()>` 是一个函数包装器,可以存储任何无参数、无返回值的可调用对象(函数、lambda表达式等)
|
|
||||||
- const 表示这个参数不会被修改
|
|
||||||
- 1.15C++引用 表示通过引用传递,避免复制开销
|
|
||||||
|
|
||||||
第二个参数 `const std::chrono::time_point<Clock, Duration>& time_point:`
|
|
||||||
|
|
||||||
- `std::chrono::time_point` 是C++标准库中表示时间点的类型
|
|
||||||
- Clock 是模板参数,指定使用哪种时钟(比如系统时钟或稳定时钟)
|
|
||||||
- Duration 是时间精度的类型(如纳秒、微秒等)
|
|
||||||
- const 和 & 的含义同上
|
|
||||||
|
|
||||||
### 为什么要使用模板实现
|
|
||||||
|
|
||||||
#### 灵活性和可扩展性
|
|
||||||
|
|
||||||
```16:17:libtimer/include/everest/timer.hpp
|
|
||||||
// template <typename TimerClock = date::steady_clock> class Timer {
|
|
||||||
template <typename TimerClock = date::utc_clock> class Timer {
|
|
||||||
```
|
|
||||||
|
|
||||||
从代码中可以看到,Timer类默认使用`date::utc_clock`作为时钟类型,但通过模板参数可以灵活地更换其他时钟类型。这种设计允许用户根据需要选择不同的时钟实现,比如:
|
|
||||||
|
|
||||||
- `date::steady_clock`:单调递增时钟
|
|
||||||
- `date::utc_clock`:UTC时钟
|
|
||||||
- `std::chrono`中的其他时钟类型
|
|
||||||
|
|
||||||
timer是如何通过模板实现自动适配不同时间类型
|
|
||||||
|
|
||||||
#### 类型安全
|
|
||||||
|
|
||||||
```69:76:libtimer/include/everest/timer.hpp
|
|
||||||
template <class Clock, class Duration = typename Clock::duration>
|
|
||||||
void at(const std::function<void()>& callback, const std::chrono::time_point<Clock, Duration>& time_point) {
|
|
||||||
this->stop();
|
|
||||||
|
|
||||||
this->callback = callback;
|
|
||||||
|
|
||||||
this->at(time_point);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
在`at()`方法中使用模板参数`Clock`和`Duration`,这样可以:
|
|
||||||
|
|
||||||
- 在编译时确保时间点类型的正确性
|
|
||||||
- 支持不同精度的时间单位(如秒、毫秒、微秒等)
|
|
||||||
- 避免运行时类型转换带来的开销
|
|
||||||
|
|
||||||
#### 通用性
|
|
||||||
|
|
||||||
```101:108:libtimer/include/everest/timer.hpp
|
|
||||||
template <class Rep, class Period>
|
|
||||||
void interval(const std::function<void()>& callback, const std::chrono::duration<Rep, Period>& interval) {
|
|
||||||
this->stop();
|
|
||||||
|
|
||||||
this->callback = callback;
|
|
||||||
|
|
||||||
this->interval(interval);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
`interval()`方法使用模板参数`Rep`和`Period`,这使得函数可以接受任何符合`std::chrono::duration`概念的时间间隔类型,比如:
|
|
||||||
|
|
||||||
- `std::chrono::seconds`
|
|
||||||
- `std::chrono::milliseconds`
|
|
||||||
- 自定义的时间单位
|
|
||||||
|
|
||||||
#### 日志回放功能
|
|
||||||
|
|
||||||
```2:3:libtimer/README.md
|
|
||||||
===========================================
|
|
||||||
EVerest is aiming to enable logfile replay. All EVerest components have to utilize this library for time (and delay) related things in order to enable accelerated logfile replay speed in the future.
|
|
||||||
```
|
|
||||||
|
|
||||||
从README可以看出,这个库的主要目的是支持日志回放功能。使用模板可以让时钟类型可配置,这样在回放模式下可以使用模拟时钟来加速或减速时间流逝,而在正常模式下使用实际的系统时钟。
|
|
||||||
|
|
||||||
#### 性能优化
|
|
||||||
|
|
||||||
- **模板代码在编译时展开,没有运行时开销**
|
|
||||||
- 编译器可以针对具体的时钟类型进行优化
|
|
||||||
- 避免了虚函数调用和类型擦除带来的性能损失
|
|
||||||
|
|
||||||
通过使用模板,这个Timer类实现了高度的灵活性和类型安全,同时保持了良好的性能,这对于需要精确时间控制的EVerest框架来说是非常重要的。
|
|
||||||
@ -1,196 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-10-28 18:11
|
|
||||||
updated: 2024-12-03 21:45
|
|
||||||
tags:
|
|
||||||
- spring
|
|
||||||
- 后端
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
# 概述
|
|
||||||
|
|
||||||
## 介绍
|
|
||||||
|
|
||||||
Spring框架是企业使用最多的框架,没有之一。Spring是一站式框架,称之为一站式框架的原因是Spring可以整合其他框架。Spring主要用来开发Java应用,Spring 可以被看作是一个大型工厂。
|
|
||||||
|
|
||||||
Spring工厂的作用就是==生产和管理 Spring 容器中的Bean==,控制反转Spring IOC和面向切面编程Spring AOP,Spring 致力于Java应用各层的解决方案。
|
|
||||||
|
|
||||||
要学习Spring的内容如下:
|
|
||||||
|
|
||||||
- IoC:控制反转
|
|
||||||
- DI:[[../编程模型及方法/依赖注入|依赖注入]]
|
|
||||||
- Spring AOP:面向切面编程技术,为Spring事务管理打下基础。
|
|
||||||
- Spring Transaction management:Spring事务管理。
|
|
||||||
- Spring Web MVC(不包含在本课程内,后面单独学习):简称Spring MVC框架,用来简化JavaWEB开发,当使用Spring MVC框架后,就不用再编写Servlet了。也就不再需要itcast-tools工具中BaseServlet类了。
|
|
||||||
- Spring与其他框架整合:因为我们只学习过MyBatis框架,所以当前我们只学习Spring整合MyBatis框架。
|
|
||||||
|
|
||||||
## spring优点
|
|
||||||
|
|
||||||
Spring优点主要表现会如下4点:
|
|
||||||
|
|
||||||
|
|
||||||
### 方便解耦
|
|
||||||
|
|
||||||
Spring的主要作用就是为代码解耦,降低代码间的耦合度。
|
|
||||||
|
|
||||||
Spring 提供了IOC控制反转,由容器管理对象,对象的依赖关系,现在由容器完成。
|
|
||||||
|
|
||||||
### AOP 编程的支持
|
|
||||||
|
|
||||||
通过 Spring 提供的 AOP功能,方便进行面向切面的编程。
|
|
||||||
|
|
||||||
### 支持声明式事务处理
|
|
||||||
|
|
||||||
通过配置就可以完成对事务的管理,无需手动编程,让开发人员可以从繁杂的事务管理代码中解脱出来,从而提高开发效率和质量。
|
|
||||||
|
|
||||||
### 方便集成各种优秀框架
|
|
||||||
|
|
||||||
Spring 不排斥各种优秀的开源框架,相反 Spring 可以降低各种框架的使用难度,Spring 提供了对各种优秀框架,比如:Struts、Hibernate、MyBatis、SpringBoot等的直接支持。
|
|
||||||
|
|
||||||
# Spring体系结构
|
|
||||||
|
|
||||||
Spring框架至今已集成了20多个模块,这些模块分布在以下模块中:
|
|
||||||
|
|
||||||
- 核心容器(Core Container)
|
|
||||||
- 数据访问/集成(Data Access/Integration)层
|
|
||||||
- Web层
|
|
||||||
- AOP(Aspect Oriented Programming)模块
|
|
||||||
- 植入(Instrumentation)模块
|
|
||||||
- 消息传输(Messaging)
|
|
||||||
- 测试(Test)模块
|
|
||||||
|
|
||||||
Spring体系结构如下图:
|
|
||||||
|
|
||||||
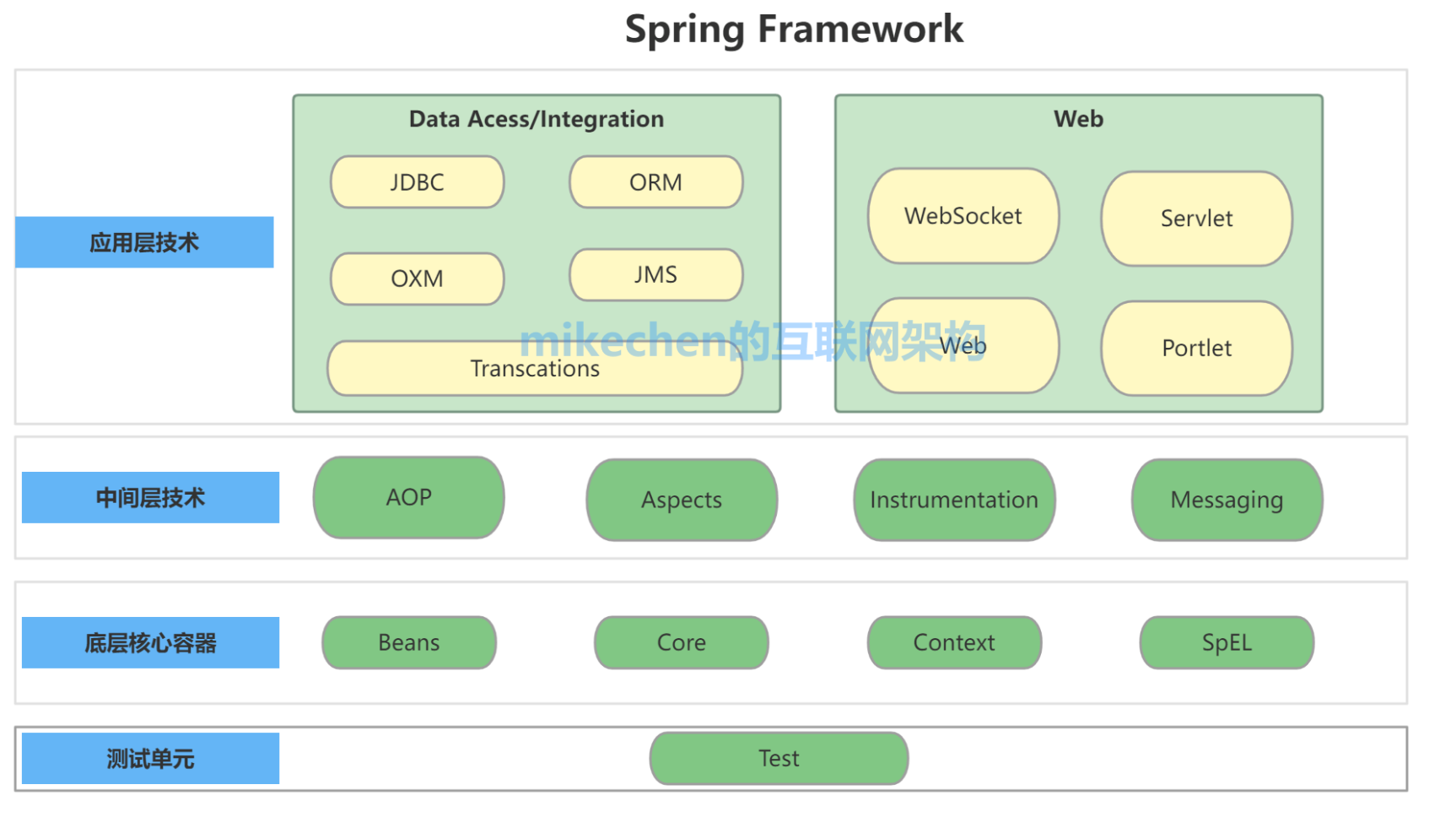
|
|
||||||
|
|
||||||
## Spring Core核心容器
|
|
||||||
|
|
||||||
Spring的核心容器是其他模块建立的基础,由Spring-core、Spring-beans、Spring-context、Spring-context-support和Spring-expression(String表达式语言)等模块组成。
|
|
||||||
|
|
||||||
- Spring-core模块:提供了框架的基本组成部分,包括控制反转(Inversion of Control,IOC)和依赖注入(Dependency Injection,DI)功能。
|
|
||||||
- Spring-beans模块:提供了BeanFactory,是工厂模式的一个经典实现,==Spring将管理对象称为Bean==。
|
|
||||||
- Spring-context模块:建立在Core和Beans模块的基础之上,提供一个框架式的对象访问方式,是访问定义和配置的任何对象的媒介。ApplicationContext接口是Context模块的焦点。
|
|
||||||
- Spring-context-support模块:支持整合第三方库到Spring应用程序上下文,特别是用于高速缓存(EhCache、JCache)和任务调度(CommonJ、Quartz)的支持。Spring-expression模块:提供了强大的表达式语言去支持运行时查询和操作对象图。这是对JSP2.1规范中规定的统一表达式语言(Unified EL)的扩展。该语言支持设置和获取属性值、属性分配、方法调用、访问数组、集合和索引器的内容、逻辑和算术运算、变量命名以及从Spring的IOC容器中以名称检索对象。它还支持列表投影、选择以及常用的列表聚合。
|
|
||||||
|
|
||||||
核心容器提供Spring框架的基本功能,spring以bean的方式组织和管理Java应用的各个组件及其关系,spring使用BeanFactory来产生和管理Bean,是工厂模式的实现。
|
|
||||||
|
|
||||||
BeanFactory通过控制反转(IOC)模式将应用程序的配置和依赖性(类与类之间的关系)规范 与 实际的应用程序代码分开(尤指业务代码),从而降低了类与类之间的耦合度。
|
|
||||||
|
|
||||||
## AOP面向切面编程
|
|
||||||
|
|
||||||
Spring-aop模块:提供了一个符合AOP要求的面向切面的编程实现,允许定义方法拦截器和切入点,将代码按照功能进行分离,以便干净地解耦。
|
|
||||||
Spring-aspects模块:提供了与AspectJ的集成功能,AspectJ是一个功能强大且成熟的AOP框架。
|
|
||||||
AOP的实现原理为动态代理技术
|
|
||||||
|
|
||||||
## Spring Context模块
|
|
||||||
|
|
||||||
Spring上下文是一个配置文件,向spring提供上下文信息,spring上下文包括企业服务。
|
|
||||||
|
|
||||||
## Spring Web模块
|
|
||||||
|
|
||||||
Web层由Spring-web、Spring-webmvc、Spring-websocket和Portlet模块组成。
|
|
||||||
|
|
||||||
- Spring-web模块:提供了基本的Web开发集成功能,例如多文件上传功能、使用Servlet监听器初始化一个IOC容器以及Web应用上下文。
|
|
||||||
- Spring-webmvc模块:也称为Web-Servlet模块,包含用于web应用程序的Spring MVC和REST Web Services实现。Spring MVC框架提供了领域模型代码和Web表单之间的清晰分离,并与Spring Framework的所有其他功能集成。
|
|
||||||
- Spring-websocket模块:Spring4.0以后新增的模块,它提供了WebSocket和SocketJS的实现。
|
|
||||||
- Portlet模块:类似于Servlet模块的功能,提供了Portlet环境下的MVC实现。
|
|
||||||
|
|
||||||
## Spring [[../编程模型及方法/DAO|DAO]]模块
|
|
||||||
|
|
||||||
提供了一个[[../编程语言/Java/JDBC|JDBC]]的抽象层和异常层次结构,消除了烦琐的JDBC编码和数据库厂商特有的错误代码解析, 用于简化JDBC。
|
|
||||||
|
|
||||||
## Spring ORM模块
|
|
||||||
|
|
||||||
Spring插入了若干个[[../编程模型及方法/ORM|ORM]]框架,提供了ORM对象的关系工具,其中包括Hibernate,JDO和IBatisSQL Map等,所有这些都遵从Spring的通用事务和DAO异常层次结构
|
|
||||||
|
|
||||||
## Spring MVC模块
|
|
||||||
|
|
||||||
Sping [[../编程模型及方法/MVC|MVC]]框架是一个全功能的构建Web应用程序的MVC实现。
|
|
||||||
|
|
||||||
SpringMVC框架提供清晰的角色划分:控制器、验证器、命令对象、表单对象和模型对象、分发器、处理器映射和视图解析器,Spring支持多种视图技术。
|
|
||||||
|
|
||||||
Spring MVC 的工作流程:
|
|
||||||
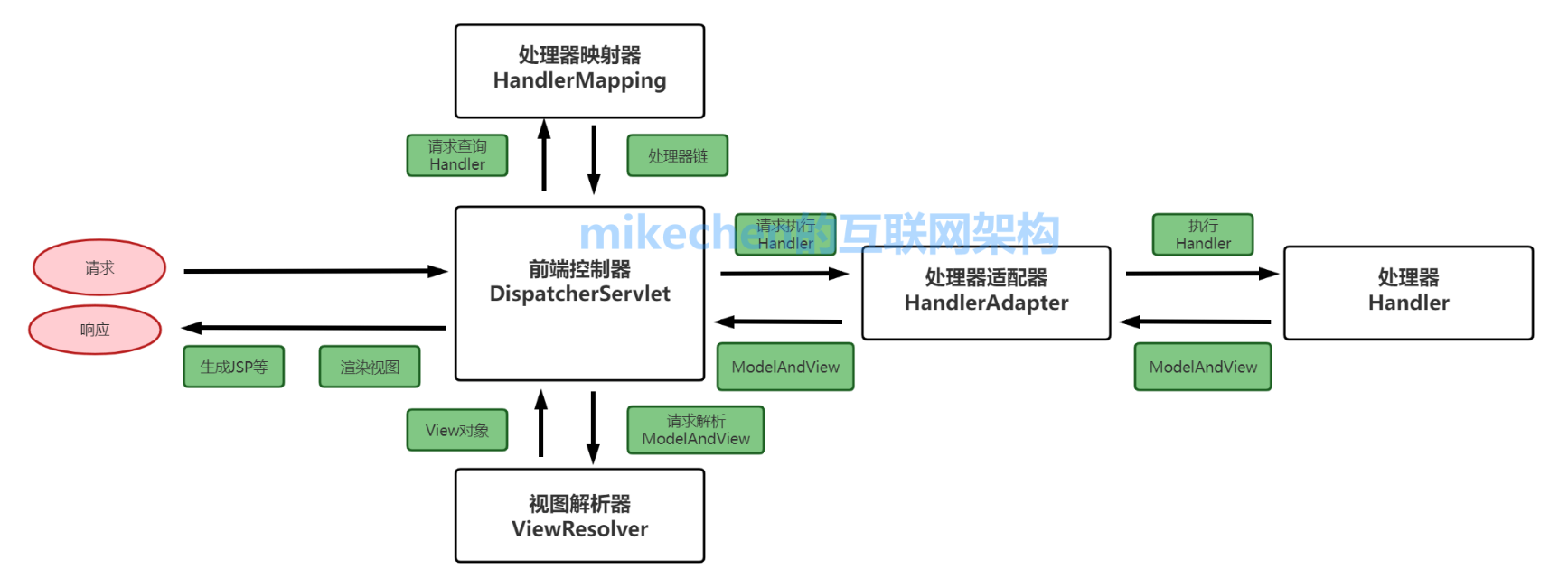
|
|
||||||
(1) 客户端发送请求,请求到达 DispatcherServlet 主控制器。
|
|
||||||
(2) DispatcherServlet 控制器调用 HandlerMapping 处理。
|
|
||||||
(3) HandlerMapping 负责维护请求和 Controller 组件对应关系。 HandlerMapping 根据请求调用对应的 Controller 组件处理。
|
|
||||||
(4) 执行 Controller 组件的业务处理,需要访问数据库,可以调用 DAO 等组件。
|
|
||||||
(5)Controller 业务方法处理完毕后,会返回一个 ModelAndView 对象。该组件封装了模型数据和视图标识。
|
|
||||||
(6)Servlet 主控制器调用 ViewResolver 组件,根据 ModelAndView 信息处理。定位视图资源,生成视图响应信息。
|
|
||||||
(7)控制器将响应信息给用户输出。
|
|
||||||
|
|
||||||
# 原理
|
|
||||||
|
|
||||||
## IoC
|
|
||||||
|
|
||||||
Spring IoC是Inversion of Control的缩写,多数书籍翻译成“控制反转”,它是Spring框架的核心。
|
|
||||||
|
|
||||||
Spring IOC用于==管理Java对象之间的依赖关系==,==将对象的创建、组装、管理交给框架来完成==,而不是由开发者手动完成。Spring提出了对象工厂的概念,由Spring工厂来管理对象的生命周期。所谓对象生命周期指的是==从对象的创建一直到对象的销毁都由Spring来管理==。我们无需再自己new对象,而是从Spring工厂中获取需要的对象。甚至**对象的依赖也由工厂来注入,无需手动注入依赖**。
|
|
||||||
|
|
||||||
IOC不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合、更优良的程序。
|
|
||||||
|
|
||||||
传统应用程序都是由我们在类内部主动创建依赖对象,从而导致**类与类之间高耦合**,难于测试,有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,如下图所示:
|
|
||||||

|
|
||||||
上图引入了IOC容器,使得A、B、C、D这4个对象没有了耦合关系,齿轮之间的传动全部依靠“第三方”了,全部对象的控制权全部上缴给“第三方”IOC容器。
|
|
||||||
|
|
||||||
所以,IOC借助于“第三方”实现具有依赖关系的对象之间的解耦,使程序更优良。
|
|
||||||
|
|
||||||
Spring IOC的实现原理,如下图所示:
|
|
||||||
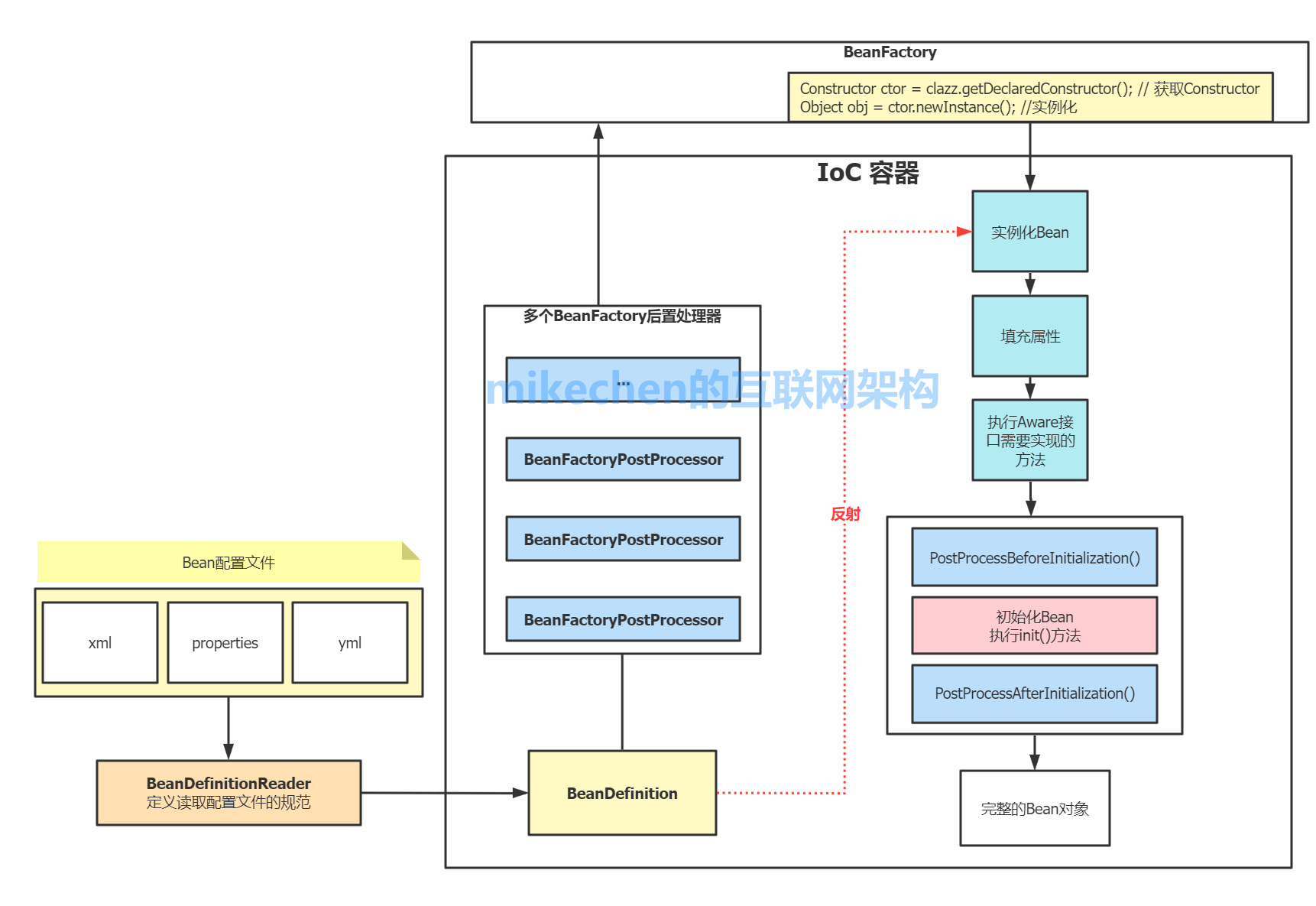
|
|
||||||
IOC容器和对象的创建过程如下:
|
|
||||||
|
|
||||||
- 定义Bean:在配置文件或者类上使用注解定义Bean,例如@Component、@Service等。
|
|
||||||
- 实例化Bean:当应用程序需要使用Bean时,Spring容器会检查是否已经实例化该Bean,如果没有,则根据配置信息实例化该Bean。
|
|
||||||
- 组装Bean:Spring容器会检查该Bean是否有依赖关系,如果有,则将依赖的其他Bean注入到该Bean中。
|
|
||||||
- 提供Bean:Spring容器将实例化的Bean提供给应用程序使用。
|
|
||||||
|
|
||||||
## Spring依赖注入原理
|
|
||||||
|
|
||||||
[[../编程模型及方法/依赖注入|依赖注入]](Dependency Injection,DI)是Spring框架的一个核心特性,它通过配置或者注解的方式,将一个对象依赖的其他对象注入进来。
|
|
||||||
|
|
||||||
如下图所示:
|
|
||||||
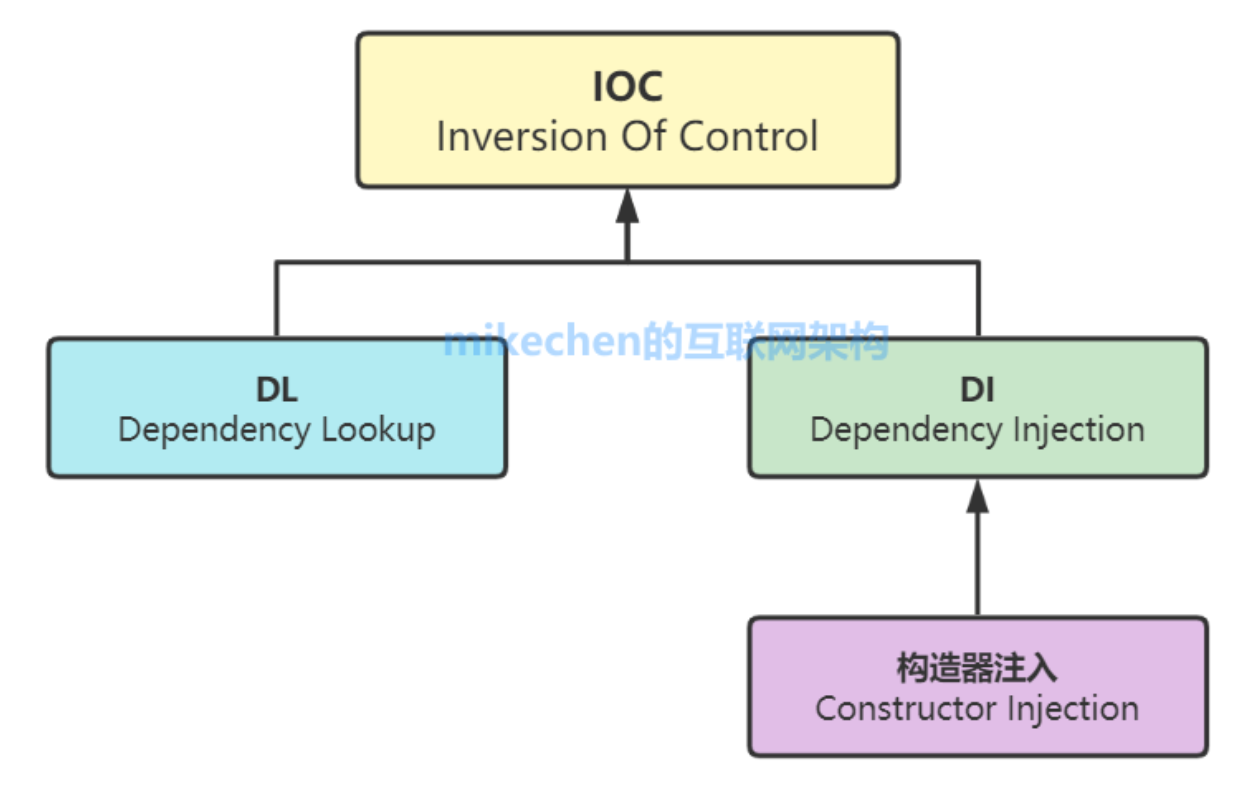
|
|
||||||
通过上图可以看出:依赖注入是实现控制反转(Inversion of Control,IoC)的一种具体实现方式。
|
|
||||||
|
|
||||||
在Spring中,实现依赖注入通常有三种方式:
|
|
||||||
|
|
||||||
1. 构造函数注入(Constructor Injection):通过==对象的构造函数==来注入依赖对象。
|
|
||||||
|
|
||||||
2. 属性注入(Property Injection):通过==对象的Setter方法==来注入依赖对象。
|
|
||||||
|
|
||||||
3. 接口注入(Interface Injection):通过对象实现的接口来注入依赖对象。
|
|
||||||
|
|
||||||
## Spring AOP原理
|
|
||||||
|
|
||||||
Spring AOP (Aspect Orient Programming),直译过来就是 ==面向切面编程==,AOP 是一种编程思想,是面向对象编程的一种补充。
|
|
||||||
|
|
||||||
面向切面编程,实现==在不修改源代码的情况下给程序动态统一添加额外功能的一种技术==,如下图所示:
|
|
||||||
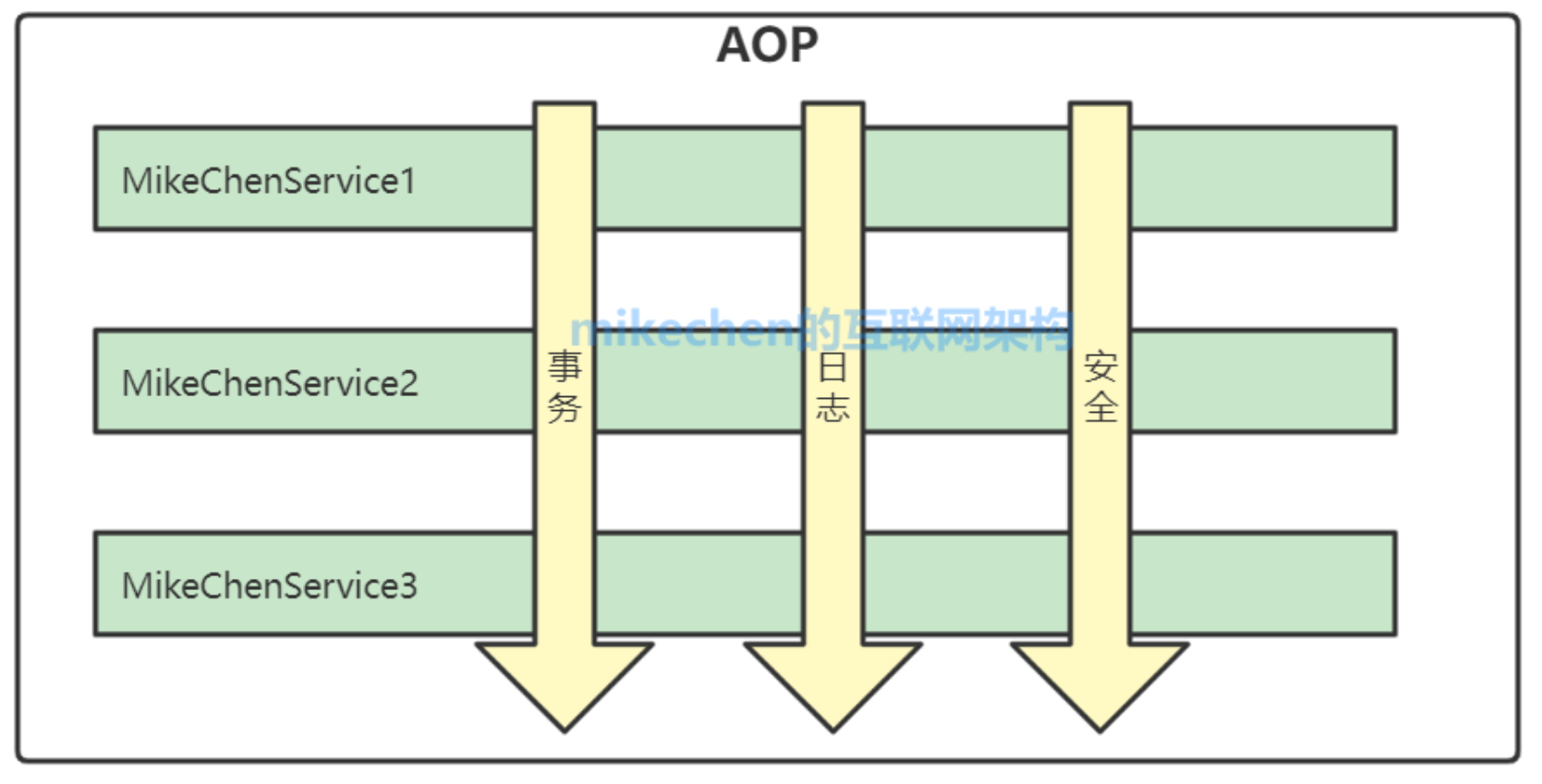
|
|
||||||
Spring AOP 实现 AOP 采用的是[[./动态代理|动态代理]]的方式,**通过代理对象实现对目标对象的方法进行拦截,从而达到切面的效果**。
|
|
||||||
|
|
||||||
在 Spring AOP 中,代理对象主要有两种类型:
|
|
||||||
|
|
||||||
JDK 动态代理:基于接口的代理实现,通过实现 JDK 的 InvocationHandler 接口来定义拦截器,并使用 Proxy 类生成代理对象。
|
|
||||||
|
|
||||||
CGLIB动态代理:基于类的代理实现,通过继承目标对象来实现代理,不需要目标对象实现任何接口。
|
|
||||||
|
|
||||||
Spring AOP的应用场景,例如:日志记录、性能监控、事务管理、权限验证等。
|
|
||||||
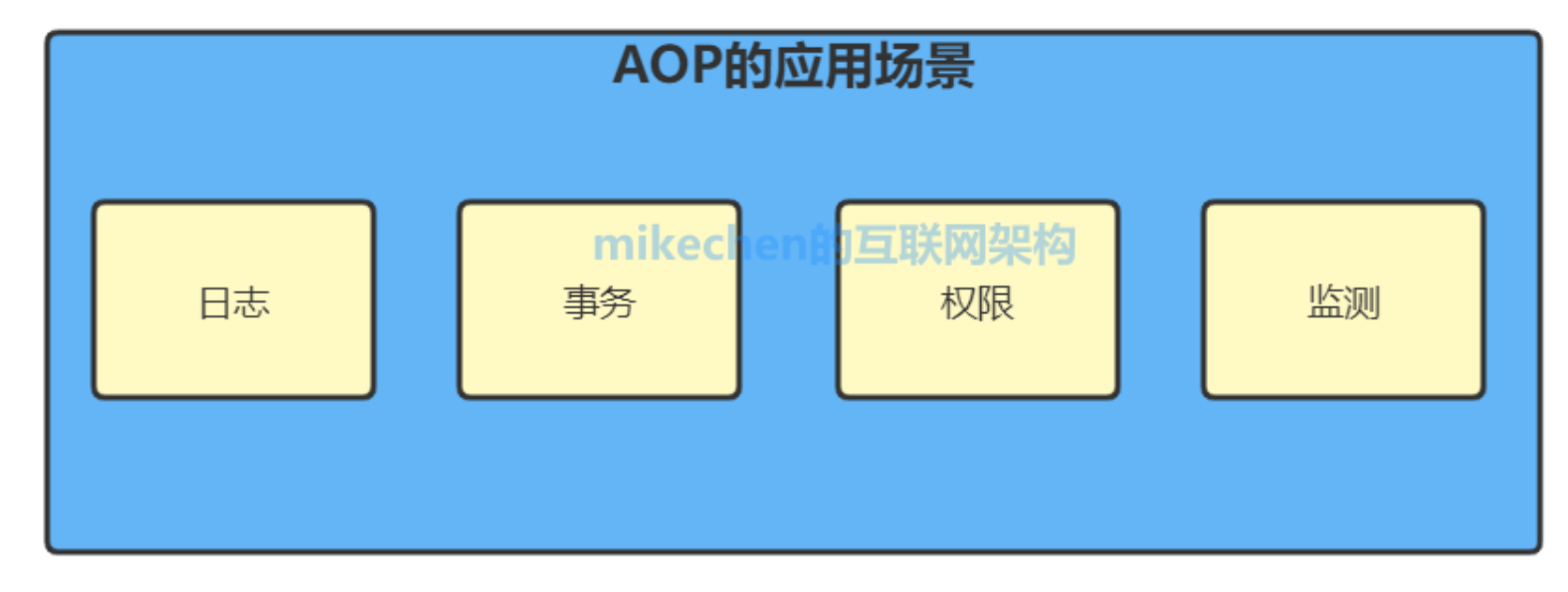
|
|
||||||
|
|
||||||
## spring事务原理
|
|
||||||
|
|
||||||
Spring事务管理有两种方式:**编程式事务管理**、**声明式事务管理**。
|
|
||||||

|
|
||||||
在 Spring 中,**声明式事务是通过 AOP 技术实现的**,当 Spring 容器加载时,它会为每个带有 @Transactional 注解的方法创建一个动态代理对象。
|
|
||||||
|
|
||||||
如下所示:
|
|
||||||
|
|
||||||
```java
|
|
||||||
@Transaction
|
|
||||||
public void insert(String userName){
|
|
||||||
this.jdbcTemplate.update("insert into t_user (name) values (?)", userName);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Spring事务的本质其实就是Spring AOP和数据库事务,Spring 将数据库的事务操作提取为==切面==,通过AOP在方法执行前后增加数据库事务操作。
|
|
||||||
@ -1,306 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-10-30 18:12
|
|
||||||
updated: 2024-12-03 21:46
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
# 关于代理
|
|
||||||
|
|
||||||
## 代理的概述
|
|
||||||
|
|
||||||
### 什么是动态代理
|
|
||||||
|
|
||||||
==使用 jdk 的[[./反射机制|反射机制]],创建对象的能力, 创建的是代理类的对象==。
|
|
||||||
|
|
||||||
- 动态:在程序执行时,调用 jdk 提供的方法才能创建代理类的对象。
|
|
||||||
- jdk 动态代理,必须有接口,目标类必须实现接口, 没有接口时,需要使用 cglib 动态代理
|
|
||||||
|
|
||||||
### 动态代理能做什么
|
|
||||||
|
|
||||||
==可以在不改变原来目标方法功能的前提下, 可以在代理中增强自己的功能代码。==
|
|
||||||
|
|
||||||
例如实际开发中,你所在的项目中,有一个功能是其他人(公司的其它部门,其它小组的人)写好的,你可以使用。你发现这个功能,现在还缺点,不能完全满足我项目的需要。 我需要在gn.print()执行后,需要自己在增加代码。用代理实现 gn.print()调用时, 增加自己代码, 而不用去改原来的 GoNong文件。
|
|
||||||
|
|
||||||
```java
|
|
||||||
// GoNong.class
|
|
||||||
GoNong gn = new GoNong();
|
|
||||||
gn.print();
|
|
||||||
```
|
|
||||||
|
|
||||||
注意,不知道源代码,不能使用重写,而且你要用写好的功能想要去扩展功能,就只能先把写好的方法执行一边,然后再代理中扩展,重写的话,原来写好的方法也没了
|
|
||||||
|
|
||||||
### 什么是代理
|
|
||||||
|
|
||||||
#### 生活中的代理
|
|
||||||
|
|
||||||
代理就是中介、代购、商家等。
|
|
||||||
|
|
||||||
例如留学中介就是一个代理,我想上美国的一所大学,但是我没办法去这个大学实地考察,也没办法要这个大学的联系方式,并且这个大学拒绝个人去访问它。但是这个大学在国内把招生业务委派给了一个留学中介。这样我就可以去和留学中介交谈,留学中介可以与美国大学联系。留学中介会从我这里收取额外的中介费。
|
|
||||||
|
|
||||||
在以上的案例中,学校是目标,留学中介是代理,我是客户。它们具有以下特点:
|
|
||||||
|
|
||||||
- 中介和代理他们要做的事情是一致的: 招生。
|
|
||||||
- 中介是学校代理, 学校是目标。
|
|
||||||
- 我—中介(学校介绍,办入学手续)----美国学校。
|
|
||||||
- 中介是代理,不能白干活,需要收取费用。
|
|
||||||
- 代理不让你访问到目标。
|
|
||||||
|
|
||||||
#### 为什么要找中介
|
|
||||||
|
|
||||||
- 中介是专业的,方便
|
|
||||||
- 我现在不能自己去找学校。 我没有能力访问学校。 或者美国学校不接收个人来访。
|
|
||||||
- 买东西都是商家卖, 商家是某个商品的代理, 你个人买东西, 肯定不会让你接触到厂家的。
|
|
||||||
|
|
||||||
### 开发中的代理模式(代理)
|
|
||||||
|
|
||||||
代理模式是指,当一个对象(目标)无法直接使用时,可以在该客户端和目标类之间创建一个中介,这个中介就是代理。
|
|
||||||
|
|
||||||
在实际开发中有这样情况,有一个A类,有一个C类,但是C类不允许A类直接访问,这样我们可以创建一个A类和C类之间的B类,C类允许B类访问,这样我们可以在A类中访问B类,然后B类在访问C类,这样就相当于在A类中间接访问到了C类。其中==A类是客户类,B类是代理类,C类是目标类==。另外,我可以在B类中添加一些内容,意味着功能增强。
|
|
||||||
|
|
||||||
#### 使用代理模式的作用
|
|
||||||
|
|
||||||
- 功能增强: 在你原有的功能上,增加了额外的功能。 新增加的功能,叫做功能增强。 (例如,留学中介要收取额外的费用)
|
|
||||||
- 控制访问: 代理类不让你访问目标,例如商家不让用户访问厂家。(就跟房屋中介肯定不会给房东电话给你,否则它们怎么赚中介费)
|
|
||||||
|
|
||||||
### 实现代理的方式
|
|
||||||
|
|
||||||
> 实现代理的方式有:静态代理,动态代理
|
|
||||||
|
|
||||||
# 静态代理
|
|
||||||
|
|
||||||
## 什么是静态代理
|
|
||||||
|
|
||||||
静态代理:代理类是==手工创建的==,代理的**目标类是固定的**。
|
|
||||||
|
|
||||||
## 静态代理的实现步骤
|
|
||||||
|
|
||||||
> 模拟一个用户购买u盘的行为,其中用户是客户端类,商家是代理类,厂家是目标类,商家和厂家都是卖U盘的,应该把卖U盘这个动作抽象为一个接口。
|
|
||||||
|
|
||||||
1.创建一个接口,定义卖u盘的方法, 表示你的厂家和商家做的事情。
|
|
||||||
|
|
||||||
```java
|
|
||||||
// 表示功能的,厂家,商家都要完成的功能
|
|
||||||
public interface UsbSell {
|
|
||||||
//定义方法 参数 amount:表示一次购买的数量,暂时不用
|
|
||||||
//返回值表示一个u盘的价格。
|
|
||||||
float sell(int amount);
|
|
||||||
|
|
||||||
//可以多个其它的方法
|
|
||||||
//void print();
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
2.创建厂家类,实现1步骤的接口
|
|
||||||
|
|
||||||
```java
|
|
||||||
//目标类:金士顿厂家, 不接受用户的单独购买。
|
|
||||||
public class UsbKingFactory implements UsbSell {
|
|
||||||
@Override
|
|
||||||
public float sell(int amount) {
|
|
||||||
System.out.println("目标类中的方法调用 , UsbKingFactory 中的sell ");
|
|
||||||
//一个128G的u盘是 85元。
|
|
||||||
//后期根据amount ,可以实现不同的价格,例如10000个,单击是80, 50000个75
|
|
||||||
return 85.0f;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
3.创建商家,就是代理类,也需要实现1步骤中的接口。
|
|
||||||
|
|
||||||
```c
|
|
||||||
// taobao是一个商家,代理金士顿u盘的销售。
|
|
||||||
public class TaoBao implements UsbSell {
|
|
||||||
// 声明 商家代理的厂家具体是谁
|
|
||||||
// private修饰为了控制访问,不让客户知道厂家是谁
|
|
||||||
private UsbKingFactory factory = new UsbKingFactory();
|
|
||||||
|
|
||||||
@Override
|
|
||||||
// 实现销售u盘功能
|
|
||||||
public float sell(int amount) {
|
|
||||||
// 向厂家发送订单,告诉厂家,我买了u盘,厂家发货
|
|
||||||
float price = factory.sell(amount); //厂家的价格。
|
|
||||||
// 商家 需要加价, 也就是代理要增加价格。
|
|
||||||
price = price + 25; //增强功能,代理类在完成目标类方法调用后,增强了功能。
|
|
||||||
// 在目标类的方法调用后,你做的其它功能,都是增强的意思。
|
|
||||||
System.out.println("淘宝商家,给你返一个优惠券,或者红包");
|
|
||||||
|
|
||||||
// 增加的价格
|
|
||||||
return price;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
public class WeiShang implements UsbSell {
|
|
||||||
//代理的是 金士顿,定义目标厂家类
|
|
||||||
private UsbKingFactory factory = new UsbKingFactory();
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public float sell(int amount) {
|
|
||||||
//调用目标方法
|
|
||||||
float price = factory.sell(amount);
|
|
||||||
//只增加1元
|
|
||||||
price = price + 1;
|
|
||||||
return price;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
4.创建客户端类,调用商家的方法买一个u盘。
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class Customer {
|
|
||||||
public static void main(String[] args) {
|
|
||||||
// 通过淘宝卖
|
|
||||||
// 下载了淘宝的app
|
|
||||||
/*
|
|
||||||
TaoBao taoBao = new TaoBao();
|
|
||||||
// 通过代理类,实现购买u盘,增加了优惠券,红包等等
|
|
||||||
float price = taoBao.sell(1);
|
|
||||||
System.out.println("淘宝的价格:" + price);
|
|
||||||
*/
|
|
||||||
|
|
||||||
// 取得微商的联系方式
|
|
||||||
WeiShang weiShang = new WeiShang();
|
|
||||||
// 通过微商代理,实现购买u盘,增加了优惠券,红包等等
|
|
||||||
float price = weiShang.sell(1);
|
|
||||||
System.out.println("通过微商购买的价格:"+ price);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
分析问题:
|
|
||||||
|
|
||||||
- 以上实例,若只有一个目标类,如金士顿厂家,商家只需要和这个厂家联系就行。但是如果又有一个闪迪厂家,那么得重写一套代理类,因为一个代理类中只能指定一个厂家,如以上的淘宝类,制定了厂家是金士顿,就不能在指定闪迪厂家,只能重新新建一个代理类,在这个代理类中指定厂家是闪迪,微商也是一样,要来一个专门代理闪迪的微商。如果有100个厂家,那么就要写200个代理类。
|
|
||||||
- 如果UsbSell接口多了个退货功能,那么所有的目标类和代理类都要修改。
|
|
||||||
|
|
||||||
## 静态代理的优缺点
|
|
||||||
|
|
||||||
### 优点
|
|
||||||
|
|
||||||
- 实现简单
|
|
||||||
- 容易理解
|
|
||||||
|
|
||||||
### 缺点
|
|
||||||
|
|
||||||
(当你的项目中,目标类和代理类很多时候,有以下的缺点:)
|
|
||||||
|
|
||||||
- 当目标类增加了,代理类可能也需要成倍的增加。 代理类数量过多。
|
|
||||||
- 当你的接口中功能增加了,或者修改了,会影响众多的实现类,厂家类,代理都需要修改。影响比较多。
|
|
||||||
|
|
||||||
简而言之,静态代理容易理解,代码好写,但是各个类之间**耦合度太高**,一旦扩展就有问题
|
|
||||||
|
|
||||||
# 动态代理
|
|
||||||
|
|
||||||
## 什么是动态代理
|
|
||||||
|
|
||||||
动态代理就是在程序执行过程(动态)中,使用jdk的[[./反射机制|反射机制]],创建代理类对象, 并动态的指定要代理目标类。换句话说: ==动态代理是一种创建java对象的能力==,让你不用自己写代理类的java程序,然后new对象。而是直接用jdk创建代理类对象。这样我不关心代理类是谁,我只知道它能增强功能,并且通过它我可以找到目标类。(类似暗下交易)
|
|
||||||
|
|
||||||
## 动态代理的优点
|
|
||||||
|
|
||||||
- 动态代理中目标类即使很多,但是代理类数量可以很少,当你修改了接口中的方法时,不会影响代理类(压根就不用写代理类了,这个代理类是jdk创建的,只是起到一个中介的功能)。符合OCP原则
|
|
||||||
- 不用创建代理类文件,代理的目标类是灵活的,可以随意给不同目标创建代理
|
|
||||||
|
|
||||||
## 动态代理的两种实现方式
|
|
||||||
|
|
||||||
1. jdk动态代理(理解): 使用java反射包中的类和接口实现动态代理的功能。
|
|
||||||
- 反射包 java.lang.reflect , 里面有三个类 : InvocationHandler , Method, Proxy.
|
|
||||||
2. cglib动态代理(了解): cglib是第三方的工具库, 创建代理对象。
|
|
||||||
- cglib的原理是继承, cglib通过继承目标类,创建它的子类,在子类中重写父类中同名的方法, 实现功能的修改。
|
|
||||||
- 因为cglib是继承,重写方法,所以要求目标类不能是final的, 方法也不能是final的。
|
|
||||||
- cglib的要求目标类比较宽松, 只要能继承就可以了。cglib在很多的框架中使用,比如 mybatis ,spring框架中都有使用。
|
|
||||||
|
|
||||||
注意:**jdk动态代理必须有接口,对于无接口类,必须使用cglib来为它创建动态代理**
|
|
||||||
|
|
||||||
## 动态代理开发中实例
|
|
||||||
|
|
||||||
```java
|
|
||||||
// 目标完成的功能
|
|
||||||
public interface HelloService {
|
|
||||||
|
|
||||||
//打印报告, 报表
|
|
||||||
int print(String name);
|
|
||||||
}
|
|
||||||
|
|
||||||
|
|
||||||
// 目标类
|
|
||||||
public class GoNeng implements HelloService {
|
|
||||||
@Override
|
|
||||||
public int print(String name) {
|
|
||||||
System.out.println("其它人写好的个功能方法");
|
|
||||||
return 2;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
|
|
||||||
// 代理完成的功能
|
|
||||||
public class MyInvocationHandler implements InvocationHandler {
|
|
||||||
|
|
||||||
private Object target = null;
|
|
||||||
|
|
||||||
public MyInvocationHandler(Object target) {
|
|
||||||
this.target = target;
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
|
|
||||||
|
|
||||||
//我在项目中记录数据库,
|
|
||||||
//调用目标方法, 执行print()得到 2
|
|
||||||
Object res = method.invoke(target,args); //2
|
|
||||||
|
|
||||||
// 代理进行“功能增强”
|
|
||||||
//需要乘以 2的结果
|
|
||||||
if( res != null){
|
|
||||||
Integer num = (Integer)res;
|
|
||||||
res = num * 2;
|
|
||||||
}
|
|
||||||
|
|
||||||
return res;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
|
|
||||||
// 测试类
|
|
||||||
public class MyApp {
|
|
||||||
|
|
||||||
public static void main(String[] args) {
|
|
||||||
// GoNeng gn = new GoNeng();
|
|
||||||
//int num = gn.print("销售");
|
|
||||||
// System.out.println("num="+num);
|
|
||||||
|
|
||||||
// 创建目标类
|
|
||||||
GoNeng goNeng = new GoNeng();
|
|
||||||
// 代理完成的功能
|
|
||||||
InvocationHandler handler = new MyInvocationHandler(goNeng);
|
|
||||||
// 这里表示目标类必须实现一个接口,否则不能用jdk实现动态代理,只能用cglib实现动态代理
|
|
||||||
System.out.println("goNeng.getClass().getInterfaces()="+goNeng.getClass().getInterfaces()[0].getName());
|
|
||||||
HelloService proxy = (HelloService) Proxy.newProxyInstance( goNeng.getClass().getClassLoader(),
|
|
||||||
goNeng.getClass().getInterfaces(),handler);
|
|
||||||
|
|
||||||
// 代理proxy的print方法实际上是接口中的,因为再创建代理是,把目标类的构造器和实现的接口都给了代理,并且代理完成的功能也给了代理
|
|
||||||
// 代理执行print方法就去handler的invoke方法,把print方法给了method,参数“市场”给了args
|
|
||||||
int num = proxy.print("市场");
|
|
||||||
System.out.println("我们期望的 num ==" + num);
|
|
||||||
|
|
||||||
// 总之proxy,handler,目标类之间是相关联的。
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
## 实现代理的步骤
|
|
||||||
|
|
||||||
- 定义业务接口和实现:习惯性地首先定义一个接口,然后提供一个或多个实现。
|
|
||||||
- 创建调用处理器:实现`InvocationHandler`接口的类,它定义了代理实例的调用处理程序。
|
|
||||||
- 生成代理实例:通过调用`Proxy.newProxyInstance()`,传入目标类的类加载器、接口数组和调用处理器来创建。
|
|
||||||
|
|
||||||
# 动态代理与静态代理的比较
|
|
||||||
|
|
||||||
两者的核心差异在于:静态代理的代理类是==编译期就确定==下来的,而动态代理的代理类是在==运行时动态创建==的。
|
|
||||||
|
|
||||||
#### 静态代理
|
|
||||||
|
|
||||||
**静态代理通常要求程序员手动编写代理类**。这就意味着,每增加一个代理目标就得增加一个代理类,工作量大,且不具备通用性。静态代理的优势在于可以直观地看到代理逻辑,也有利于错误的排查。
|
|
||||||
|
|
||||||
#### 动态代理
|
|
||||||
|
|
||||||
**动态代理不需要显示地编写代理类**,系统通过反射等机制在运行时创建代理对象,极大地提高了代码的灵活性和可复用性。动态代理的使用使得单一代理类可以代理多种类型的主体。
|
|
||||||
@ -1,487 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-10-31 10:40
|
|
||||||
updated: 2024-12-03 21:46
|
|
||||||
tags:
|
|
||||||
- 语言特性
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
# 概念
|
|
||||||
|
|
||||||
反射机制是一种==程序在运行时动态检查和操作自身结构==的能力。它允许程序==在运行时获取类、方法、属性等信息==,甚至可以==动态地调用对象的方法、修改属性值,或者创建类实例==。反射在一些高级编程场景中非常有用,尤其是在需要动态加载类和方法的情况下,比如框架开发和插件系统。
|
|
||||||
|
|
||||||
反射的主要功能包括:
|
|
||||||
|
|
||||||
1. **获取类信息**:在运行时,可以获取一个类的名称、方法、字段、构造函数等详细信息。
|
|
||||||
2. **调用方法**:即使在编译时不知道方法的名称,也可以在运行时通过反射调用该方法。
|
|
||||||
3. **访问属性**:可以在运行时获取或设置对象的属性值。
|
|
||||||
4. **创建实例**:可以在运行时根据类名动态创建类的实例。
|
|
||||||
|
|
||||||
不过,反射也有一些限制和代价:
|
|
||||||
|
|
||||||
- **性能开销**:反射通常比直接调用方法或访问属性要慢,因为需要更多的检查和类型验证。
|
|
||||||
- **安全性和权限**:反射可以绕过一些访问修饰符的限制(如私有方法和属性),可能会导致安全隐患。
|
|
||||||
- **可维护性**:反射代码可能会使程序难以理解和调试,因为它依赖于运行时而非编译时的检查。
|
|
||||||
|
|
||||||
在 Java、C# 等语言中,反射机制广泛应用于框架(如 Spring、Hibernate)和工具库中,用来实现高度的灵活性和动态配置能力。
|
|
||||||
|
|
||||||
## 反射的意义
|
|
||||||
|
|
||||||
- 通过反射机制可以让程序创建和控制任何类的对象,==无需提前硬编码目标类==。
|
|
||||||
- 使用反射机制能够在运行时构造一个类的对象、判断一个类所具有的成员变量和方法、调用一个对象的方法。
|
|
||||||
- 反射机制是构建框架技术的基础所在,使用反射可以**避免将代码写死在框架中**。
|
|
||||||
|
|
||||||
# C语言中的实现
|
|
||||||
|
|
||||||
在C语言中实现反射机制较为困难,因为C是一种过程式编程语言,缺乏像C++、Java等语言中的面向对象特性和运行时类型信息(RTTI)。然而,仍然可以通过一些技巧和方法实现有限的反射功能:
|
|
||||||
|
|
||||||
## 使用结构体与指针
|
|
||||||
|
|
||||||
- 在C语言中,可以使用结构体来模拟对象,并通过指针访问和操作结构体的字段。这虽然不是严格意义上的反射,但可以==用于在运行时动态地处理不同类型的数据==。
|
|
||||||
- 比如,通过定义一个通用结构体,然后在运行时传递指针并手动解析其内容,实现对“成员”的访问。
|
|
||||||
|
|
||||||
```c
|
|
||||||
typedef struct {
|
|
||||||
char type[20];
|
|
||||||
int value;
|
|
||||||
} Attribute;
|
|
||||||
|
|
||||||
void printAttribute(Attribute *attr) {
|
|
||||||
printf("Type: %s, Value: %d\n", attr->type, attr->value);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
## 函数指针表
|
|
||||||
|
|
||||||
- 可以使用**函数指针表来模拟虚函数表**,从而动态地调用不同函数。这样虽然不能动态地查询类型信息,但可以实现==运行时动态地调用不同功能==的方法。
|
|
||||||
|
|
||||||
```c
|
|
||||||
typedef void (*FunctionPointer)(void);
|
|
||||||
|
|
||||||
typedef struct {
|
|
||||||
FunctionPointer func1;
|
|
||||||
FunctionPointer func2;
|
|
||||||
} FunctionTable;
|
|
||||||
|
|
||||||
void foo() { printf("foo\n"); }
|
|
||||||
void bar() { printf("bar\n"); }
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
FunctionTable table = { foo, bar };
|
|
||||||
table.func1(); // 输出 "foo"
|
|
||||||
table.func2(); // 输出 "bar"
|
|
||||||
return 0;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
## 哈希表与字符串映射
|
|
||||||
|
|
||||||
- 使用哈希表,将字符串映射到结构体字段或函数指针上,可以在运行时根据字符串键来访问数据或调用函数。
|
|
||||||
- 这种方法对于实现类似“名称-方法”或“名称-字段”的映射非常有效,可以根据字符串名称找到对应的字段或方法进行访问和操作。
|
|
||||||
|
|
||||||
```c
|
|
||||||
#include <stdio.h>
|
|
||||||
#include <string.h>
|
|
||||||
|
|
||||||
typedef struct {
|
|
||||||
char name[20];
|
|
||||||
int age;
|
|
||||||
} Person;
|
|
||||||
|
|
||||||
int getFieldOffset(const char* field) {
|
|
||||||
if (strcmp(field, "name") == 0) return offsetof(Person, name);
|
|
||||||
if (strcmp(field, "age") == 0) return offsetof(Person, age);
|
|
||||||
return -1;
|
|
||||||
}
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
Person p = {"Alice", 30};
|
|
||||||
int offset = getFieldOffset("age");
|
|
||||||
if (offset != -1) {
|
|
||||||
int* agePtr = (int*)((char*)&p + offset);
|
|
||||||
printf("Age: %d\n", *agePtr);
|
|
||||||
}
|
|
||||||
return 0;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
## 自定义元数据与代码生成
|
|
||||||
|
|
||||||
- 可以手动为每种类型定义元数据结构来描述其字段和函数,使用这些元数据实现动态访问。这类似于手动创建一套反射系统。
|
|
||||||
- 代码生成工具(如Python脚本)可以用来自动生成这些元数据结构和访问函数,避免手动定义的冗长和错误。
|
|
||||||
|
|
||||||
### 手动定义元数据结构示例
|
|
||||||
|
|
||||||
我们定义一个简单的`Person`结构体,并为它创建一个描述元数据的系统。
|
|
||||||
|
|
||||||
```c
|
|
||||||
#include <stdio.h>
|
|
||||||
#include <string.h>
|
|
||||||
#include <stdlib.h>
|
|
||||||
|
|
||||||
// 定义结构体和字段类型
|
|
||||||
typedef enum {
|
|
||||||
FIELD_TYPE_INT,
|
|
||||||
FIELD_TYPE_STRING,
|
|
||||||
} FieldType;
|
|
||||||
|
|
||||||
typedef struct {
|
|
||||||
const char *field_name;
|
|
||||||
FieldType type;
|
|
||||||
size_t offset;
|
|
||||||
} FieldMetadata;
|
|
||||||
|
|
||||||
typedef struct {
|
|
||||||
const char *type_name;
|
|
||||||
FieldMetadata *fields;
|
|
||||||
size_t field_count;
|
|
||||||
} TypeMetadata;
|
|
||||||
|
|
||||||
// 定义Person结构体
|
|
||||||
typedef struct {
|
|
||||||
char name[50];
|
|
||||||
int age;
|
|
||||||
} Person;
|
|
||||||
|
|
||||||
// 创建元数据描述Person的字段
|
|
||||||
FieldMetadata person_fields[] = {
|
|
||||||
{ "name", FIELD_TYPE_STRING, offsetof(Person, name) },
|
|
||||||
{ "age", FIELD_TYPE_INT, offsetof(Person, age) }
|
|
||||||
};
|
|
||||||
|
|
||||||
TypeMetadata person_metadata = { "Person", person_fields, 2 };
|
|
||||||
|
|
||||||
// 函数:根据字段名和元数据动态获取字段值
|
|
||||||
void print_field(const void *object, FieldMetadata *field) {
|
|
||||||
void *field_ptr = (char *)object + field->offset;
|
|
||||||
if (field->type == FIELD_TYPE_STRING) {
|
|
||||||
printf("%s: %s\n", field->field_name, (char *)field_ptr);
|
|
||||||
} else if (field->type == FIELD_TYPE_INT) {
|
|
||||||
printf("%s: %d\n", field->field_name, *(int *)field_ptr);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// 函数:打印结构体所有字段信息
|
|
||||||
void print_struct(const void *object, const TypeMetadata *metadata) {
|
|
||||||
printf("Struct %s:\n", metadata->type_name);
|
|
||||||
for (size_t i = 0; i < metadata->field_count; i++) {
|
|
||||||
print_field(object, &metadata->fields[i]);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
// 创建Person对象并设置字段值
|
|
||||||
Person p = { "Alice", 30 };
|
|
||||||
|
|
||||||
// 使用元数据打印字段信息
|
|
||||||
print_struct(&p, &person_metadata);
|
|
||||||
|
|
||||||
return 0;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 代码解析
|
|
||||||
|
|
||||||
1. **FieldMetadata**:定义字段的元数据结构,包含字段名、字段类型、字段在结构体中的偏移量。
|
|
||||||
2. **TypeMetadata**:定义类型元数据结构,包含结构体类型名、字段元数据数组、字段数目。
|
|
||||||
3. **offsetof**宏:用于==获取字段在结构体中的偏移量==,以便根据偏移量在运行时访问字段。
|
|
||||||
4. **print_field函数**:根据字段的类型打印字段值,通过字段的偏移量访问字段值。
|
|
||||||
5. **print_struct函数**:遍历结构体的所有字段并打印。
|
|
||||||
|
|
||||||
#### 关键点
|
|
||||||
|
|
||||||
- 通过 `offsetof` 宏和指针运算来访问结构体中的字段。
|
|
||||||
- 可以根据不同类型(`FIELD_TYPE_INT` 和 `FIELD_TYPE_STRING`)动态处理不同的字段类型。
|
|
||||||
- 这种自定义元数据方法是静态的,元数据是手动定义的,但通过定义结构体和元数据,可以在运行时动态获取和操作字段值,模拟了简单的反射功能。
|
|
||||||
|
|
||||||
这种方法对于处理更多类型、字段或复杂结构体可以扩展,但需手动创建元数据,适用于对性能要求较高或资源受限的场景。
|
|
||||||
|
|
||||||
### 代码生成元数据结构示例
|
|
||||||
|
|
||||||
我们可以编写一个Python脚本,自动生成C代码中的元数据结构和访问函数。这个示例会**从==json文件==中读取结构体的字段信息,并生成相应的C代码**。
|
|
||||||
|
|
||||||
#### 目标
|
|
||||||
|
|
||||||
假设我们有一个描述结构体字段的json文件,通过Python脚本读取这些描述,然后自动生成C语言元数据结构和访问函数的代码。
|
|
||||||
|
|
||||||
#### 示例结构体描述
|
|
||||||
|
|
||||||
我们将描述一个`Person`结构体,包含两个字段:`name`(字符串)和`age`(整数)。可以在Python中表示如下:
|
|
||||||
|
|
||||||
```json
|
|
||||||
{
|
|
||||||
"Person": [
|
|
||||||
{
|
|
||||||
"field_name": "name",
|
|
||||||
"field_type": "FIELD_TYPE_STRING",
|
|
||||||
"c_type": "char[50]"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"field_name": "age",
|
|
||||||
"field_type": "FIELD_TYPE_INT",
|
|
||||||
"c_type": "int"
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 创建基础代码模板文件
|
|
||||||
|
|
||||||
创建一个名为 `base_code_template.c` 的文件,内容如下:
|
|
||||||
|
|
||||||
```c
|
|
||||||
#include <stdio.h>
|
|
||||||
#include <stddef.h>
|
|
||||||
|
|
||||||
// 定义字段类型枚举
|
|
||||||
typedef enum {
|
|
||||||
FIELD_TYPE_INT,
|
|
||||||
FIELD_TYPE_STRING,
|
|
||||||
} FieldType;
|
|
||||||
|
|
||||||
// 定义字段元数据结构
|
|
||||||
typedef struct {
|
|
||||||
const char *field_name;
|
|
||||||
FieldType type;
|
|
||||||
size_t offset;
|
|
||||||
} FieldMetadata;
|
|
||||||
|
|
||||||
// 定义类型元数据结构
|
|
||||||
typedef struct {
|
|
||||||
const char *type_name;
|
|
||||||
FieldMetadata *fields;
|
|
||||||
size_t field_count;
|
|
||||||
} TypeMetadata;
|
|
||||||
|
|
||||||
// 函数:打印字段
|
|
||||||
void print_field(const void *object, FieldMetadata *field) {
|
|
||||||
void *field_ptr = (char *)object + field->offset;
|
|
||||||
if (field->type == FIELD_TYPE_STRING) {
|
|
||||||
printf("%s: %s\n", field->field_name, (char *)field_ptr);
|
|
||||||
} else if (field->type == FIELD_TYPE_INT) {
|
|
||||||
printf("%s: %d\n", field->field_name, *(int *)field_ptr);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// 函数:打印结构体所有字段
|
|
||||||
void print_struct(const void *object, const TypeMetadata *metadata) {
|
|
||||||
printf("Struct %s:\n", metadata->type_name);
|
|
||||||
for (size_t i = 0; i < metadata->field_count; i++) {
|
|
||||||
print_field(object, &metadata->fields[i]);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### Python代码生成脚本
|
|
||||||
|
|
||||||
以下Python脚本会读取结构体定义并生成C代码。它生成结构体、字段元数据、类型元数据以及用于打印的访问函数。
|
|
||||||
|
|
||||||
```python
|
|
||||||
import json
|
|
||||||
|
|
||||||
# 从JSON文件中读取结构体定义
|
|
||||||
def load_struct_definitions(filename):
|
|
||||||
with open(filename, "r") as file:
|
|
||||||
return json.load(file)
|
|
||||||
|
|
||||||
# 生成C代码的函数
|
|
||||||
def generate_code(struct_definitions):
|
|
||||||
c_code = ""
|
|
||||||
|
|
||||||
# 包含基础代码模板
|
|
||||||
with open("base_code_template.c", "r") as base_file:
|
|
||||||
c_code += base_file.read()
|
|
||||||
|
|
||||||
# 遍历每个结构体生成代码
|
|
||||||
for struct_name, fields in struct_definitions.items():
|
|
||||||
# 生成结构体定义
|
|
||||||
c_code += f"\n// 定义结构体 {struct_name}\n"
|
|
||||||
c_code += f"typedef struct {{\n"
|
|
||||||
for field in fields:
|
|
||||||
c_code += f" {field['c_type']} {field['field_name']};\n"
|
|
||||||
c_code += f"}} {struct_name};\n"
|
|
||||||
|
|
||||||
# 生成字段元数据数组
|
|
||||||
c_code += f"\n// 定义 {struct_name} 的字段元数据\n"
|
|
||||||
c_code += f"FieldMetadata {struct_name.lower()}_fields[] = {{\n"
|
|
||||||
for field in fields:
|
|
||||||
c_code += f' {{"{field["field_name"]}", {field["field_type"]}, offsetof({struct_name}, {field["field_name"]})}},\n'
|
|
||||||
c_code += "};\n"
|
|
||||||
|
|
||||||
# 生成类型元数据
|
|
||||||
c_code += f"\n// 定义 {struct_name} 的类型元数据\n"
|
|
||||||
c_code += f"TypeMetadata {struct_name.lower()}_metadata = {{\n"
|
|
||||||
c_code += f' "{struct_name}", {struct_name.lower()}_fields, {len(fields)}\n'
|
|
||||||
c_code += "};\n"
|
|
||||||
|
|
||||||
# 生成main函数示例
|
|
||||||
c_code += """
|
|
||||||
int main() {
|
|
||||||
// 创建Person对象并设置字段值
|
|
||||||
Person p = { "Alice", 30 };
|
|
||||||
|
|
||||||
// 使用元数据打印字段信息
|
|
||||||
print_struct(&p, &person_metadata);
|
|
||||||
|
|
||||||
return 0;
|
|
||||||
}
|
|
||||||
"""
|
|
||||||
return c_code
|
|
||||||
|
|
||||||
# 主程序入口
|
|
||||||
if __name__ == "__main__":
|
|
||||||
# 加载结构体定义
|
|
||||||
struct_definitions = load_struct_definitions("struct_definitions.json")
|
|
||||||
|
|
||||||
# 生成代码并写入文件
|
|
||||||
generated_code = generate_code(struct_definitions)
|
|
||||||
output_file = "generated_reflection.c"
|
|
||||||
with open(output_file, "w") as file:
|
|
||||||
file.write(generated_code)
|
|
||||||
|
|
||||||
print(f"代码已生成并写入到 {output_file} 文件中。")
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
### 生成的C代码示例
|
|
||||||
|
|
||||||
运行上面的Python脚本后,生成的`generated_reflection.c`文件会如下所示:
|
|
||||||
|
|
||||||
```c
|
|
||||||
#include <stdio.h>
|
|
||||||
#include <stddef.h>
|
|
||||||
|
|
||||||
// 定义字段类型枚举
|
|
||||||
typedef enum {
|
|
||||||
FIELD_TYPE_INT,
|
|
||||||
FIELD_TYPE_STRING,
|
|
||||||
} FieldType;
|
|
||||||
|
|
||||||
// 定义字段元数据结构
|
|
||||||
typedef struct {
|
|
||||||
const char *field_name;
|
|
||||||
FieldType type;
|
|
||||||
size_t offset;
|
|
||||||
} FieldMetadata;
|
|
||||||
|
|
||||||
// 定义类型元数据结构
|
|
||||||
typedef struct {
|
|
||||||
const char *type_name;
|
|
||||||
FieldMetadata *fields;
|
|
||||||
size_t field_count;
|
|
||||||
} TypeMetadata;
|
|
||||||
|
|
||||||
// 函数:打印字段
|
|
||||||
void print_field(const void *object, FieldMetadata *field) {
|
|
||||||
void *field_ptr = (char *)object + field->offset;
|
|
||||||
if (field->type == FIELD_TYPE_STRING) {
|
|
||||||
printf("%s: %s\n", field->field_name, (char *)field_ptr);
|
|
||||||
} else if (field->type == FIELD_TYPE_INT) {
|
|
||||||
printf("%s: %d\n", field->field_name, *(int *)field_ptr);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// 函数:打印结构体所有字段
|
|
||||||
void print_struct(const void *object, const TypeMetadata *metadata) {
|
|
||||||
printf("Struct %s:\n", metadata->type_name);
|
|
||||||
for (size_t i = 0; i < metadata->field_count; i++) {
|
|
||||||
print_field(object, &metadata->fields[i]);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// 定义结构体 Person
|
|
||||||
typedef struct {
|
|
||||||
char name[50];
|
|
||||||
int age;
|
|
||||||
} Person;
|
|
||||||
|
|
||||||
// 定义 Person 的字段元数据
|
|
||||||
FieldMetadata person_fields[] = {
|
|
||||||
{"name", FIELD_TYPE_STRING, offsetof(Person, name)},
|
|
||||||
{"age", FIELD_TYPE_INT, offsetof(Person, age)},
|
|
||||||
};
|
|
||||||
|
|
||||||
// 定义 Person 的类型元数据
|
|
||||||
TypeMetadata person_metadata = {
|
|
||||||
"Person", person_fields, 2
|
|
||||||
};
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
// 创建Person对象并设置字段值
|
|
||||||
Person p = { "Alice", 30 };
|
|
||||||
|
|
||||||
// 使用元数据打印字段信息
|
|
||||||
print_struct(&p, &person_metadata);
|
|
||||||
|
|
||||||
return 0;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### 运行与输出
|
|
||||||
|
|
||||||
编译并运行生成的C代码:
|
|
||||||
|
|
||||||
```bash
|
|
||||||
gcc generated_reflection.c -o reflection
|
|
||||||
./reflection
|
|
||||||
```
|
|
||||||
|
|
||||||
输出:
|
|
||||||
|
|
||||||
```plaintext
|
|
||||||
Struct Person:
|
|
||||||
name: Alice
|
|
||||||
age: 30
|
|
||||||
```
|
|
||||||
|
|
||||||
### 代码生成的优势
|
|
||||||
|
|
||||||
- **自动生成**:可以随时通过修改`struct_definitions`中的内容来更改结构体,避免手动更新C代码。
|
|
||||||
- **易于扩展**:可以进一步扩展Python脚本,使其支持更多的字段类型和结构体定义。
|
|
||||||
- **减少手工错误**:自动生成的代码降低了手工编码中的错误风险。
|
|
||||||
|
|
||||||
## GLib 等库
|
|
||||||
|
|
||||||
- 使用像GLib这样的C库。GLib提供了一个`GObject`系统,带有基本的反射功能,如属性访问和信号系统。GObject的反射能力虽然不如Java,但它在C语言中提供了一种实现面向对象和反射的途径。
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
C语言中没有直接的反射机制,但通过结构体、指针运算、函数指针表、哈希映射、自定义元数据等方法,可以在一定程度上实现反射的功能。这些技巧适合于对C语言特性较熟悉的开发者,尤其是在嵌入式系统或低层系统编程中。
|
|
||||||
|
|
||||||
# C++ 中的实现
|
|
||||||
|
|
||||||
在C++中,原生并不直接支持像Java或C#那样完整的反射机制,但有一些替代方案可以实现类似的功能:
|
|
||||||
|
|
||||||
## RTTI(Run-Time Type Information,运行时类型信息)
|
|
||||||
|
|
||||||
- C++提供了一些运行时类型识别功能,如`typeid`和`dynamic_cast`。这些操作允许程序在运行时检查对象的类型,但只能用于多态类型(即包含虚函数的类)。
|
|
||||||
- `typeid`可以获取类型信息,`dynamic_cast`允许在运行时安全地向下转换指针或引用。尽管这并非真正的反射机制,但在一些场景下可以起到一定的动态类型识别作用。
|
|
||||||
|
|
||||||
## 手动反射
|
|
||||||
|
|
||||||
- 可以通过宏、模板等技术来手动实现有限的反射。例如,使用宏定义一系列getter/setter函数,以便在运行时访问类的成员变量。
|
|
||||||
- 这种方法通常需要大量的代码编写,并且缺乏通用性,但在一些小规模项目中可以作为替代方案。
|
|
||||||
|
|
||||||
## 元编程(Metaprogramming)
|
|
||||||
|
|
||||||
- C++的模板元编程可以在编译期生成代码,虽然不是严格意义上的反射,但可以在编译期根据类型信息生成特定代码,达到一定的灵活性。
|
|
||||||
- C++17引入了`std::variant`和`std::any`,可以通过它们进行类型安全的动态处理。
|
|
||||||
- C++20中的`concepts`和改进的模板特性也增加了类型信息的利用率,使得模板元编程更加简便。
|
|
||||||
|
|
||||||
## 第三方库(如RTTR、Boost.TypeIndex)
|
|
||||||
|
|
||||||
- **RTTR**(Run Time Type Reflection)库:C++专门用于反射的第三方库,提供了类型、方法和属性的运行时查询和调用。
|
|
||||||
- **Boost.TypeIndex**:Boost库的一部分,扩展了RTTI功能,提供更丰富的类型信息获取支持。
|
|
||||||
- 这些库通过宏和模板来模拟反射功能,从而可以实现动态访问、调用和类型识别。
|
|
||||||
|
|
||||||
## 模块化系统和代码生成
|
|
||||||
|
|
||||||
- 在编译期通过代码生成工具(如protobuf或XML/JSON解析器)生成反射相关的代码,这样就可以在运行时访问和操作生成的代码结构。
|
|
||||||
- 这种方法需要额外的代码生成步骤,适合==大型项目或者数据驱动的场景==。
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
C++本身没有直接的反射机制,但可以通过RTTI、手动反射、模板元编程、第三方库等方式实现一定程度的反射功能。
|
|
||||||
@ -1,31 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-12-16 16:52
|
|
||||||
updated: 2024-12-16 17:08
|
|
||||||
tags:
|
|
||||||
- 工具
|
|
||||||
- AI
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
因为gpt翻译pdf不太方便,所以使用ciciai进行辅助翻译。
|
|
||||||
|
|
||||||
# 下载
|
|
||||||
|
|
||||||
下载桌面端[ciciai](https://www.ciciai.com),并安装。
|
|
||||||
|
|
||||||
# 拆分pdf
|
|
||||||
|
|
||||||
源文件对于ai来说太大了,生成答案的速度很慢,所以在提问前先对pdf进行拆分。再使用对应章节的pdf进行提问。
|
|
||||||
|
|
||||||
如下图,在adobe acrobat中,使用组织页面对源文件进行拆分。
|
|
||||||
|
|
||||||
|
|
||||||
在拆分选项中选择顶层书签,点击拆分。
|
|
||||||
|
|
||||||
然后等待acrobat将pdf按照章节拆分好。
|
|
||||||
|
|
||||||
# 翻译及问答
|
|
||||||
|
|
||||||
将文档拖入cici中,如图就能很轻松的对文档进行翻译和提问。
|
|
||||||

|
|
||||||
@ -1,38 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-11-05 16:07
|
|
||||||
updated: 2024-12-03 21:45
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
辣鸡小米手表不能识别flac格式的音乐,因此需要一个批量将falc格式的音乐转换成mp3的工具。网上找了下发现都是使用毒瘤软件格式工厂,就在git上搜了下,发现有个老外写了个类似的工具。
|
|
||||||
|
|
||||||
项目地址:<https://github.com/robinbowes/flac2mp3>
|
|
||||||
|
|
||||||
直接将项目clone下来
|
|
||||||
|
|
||||||
```shell
|
|
||||||
# wyq @ wangyq in ~ [15:48:24]
|
|
||||||
$ git clone https://github.com/robinbowes/flac2mp3.git
|
|
||||||
Cloning into 'flac2mp3'...
|
|
||||||
remote: Enumerating objects: 705, done.
|
|
||||||
remote: Counting objects: 100% (7/7), done.
|
|
||||||
remote: Compressing objects: 100% (7/7), done.
|
|
||||||
remote: Total 705 (delta 1), reused 1 (delta 0), pack-reused 698 (from 1)
|
|
||||||
Receiving objects: 100% (705/705), 469.71 KiB | 1.54 MiB/s, done.
|
|
||||||
Resolving deltas: 100% (364/364), done.
|
|
||||||
```
|
|
||||||
|
|
||||||
然后进入目录中,使用pl脚本
|
|
||||||
|
|
||||||
```she'l'l
|
|
||||||
# wyq @ wangyq in ~/flac2mp3 on git:master o [15:57:46] C:127
|
|
||||||
$ ./flac2mp3.pl /mnt/d/Music/flac/ /mnt/d/Music/mp3/
|
|
||||||
Using flac from: /usr/bin/flac
|
|
||||||
Using lame from: /usr/bin/lame
|
|
||||||
Processing directory: /mnt/d/Music/flac
|
|
||||||
Found 55 flac files
|
|
||||||
Using 1 transcoding processes.
|
|
||||||
```
|
|
||||||
|
|
||||||
等待结束
|
|
||||||
@ -1,166 +0,0 @@
|
|||||||
---
|
|
||||||
tags:
|
|
||||||
- obsidian
|
|
||||||
date: 2024-12-03 11:46
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
updated: 2024-12-03 21:53
|
|
||||||
---
|
|
||||||
|
|
||||||
## 设置
|
|
||||||
|
|
||||||
### 语言
|
|
||||||
|
|
||||||
在「设置->关于」中进行语言的切换:
|
|
||||||
|
|
||||||
|
|
||||||
### 删除文件设置
|
|
||||||
|
|
||||||
在「设置->文件与链接」中进行配置,我设置为移至软件回收站,这样删除的文件会在 Obsidian 的库目录下的一个隐藏目录中,如果发现误删还能找回来。
|
|
||||||
|
|
||||||
|
|
||||||
## 主题
|
|
||||||
|
|
||||||
目前使用 NORD 主题,在「设置->外观->主题」界面点击「管理」按钮,在弹出的界面中选择使用喜欢的主题即可。
|
|
||||||
|
|
||||||
## 字体
|
|
||||||
|
|
||||||
正文的界面字体使用雅黑
|
|
||||||
代码字体使用source code pro
|
|
||||||
|
|
||||||
## 快捷键设置
|
|
||||||
|
|
||||||
按照之前的typora的使用习惯
|
|
||||||
|
|
||||||
### 标题
|
|
||||||
|
|
||||||
> 设置 > 快捷键 > 设置为小标题 1-6 > 依次设置为 [ctrl + 1-6]
|
|
||||||
|
|
||||||
### 高亮
|
|
||||||
|
|
||||||
> 在「设置->快捷键」中进行配置,高亮->[ctrl+q]
|
|
||||||
|
|
||||||
### 格式化
|
|
||||||
|
|
||||||
[[Obsidian配置#Markdown prettifier|Obsidian配置 > Markdown prettifier]]
|
|
||||||
|
|
||||||
### 代码块
|
|
||||||
|
|
||||||
[[Obsidian配置#Code block from selection|Obsidian配置 > Code block from selection]]
|
|
||||||
使用这个插件,设置快捷键为[ctrl + shift + K],默认C语言
|
|
||||||
|
|
||||||
## 插件
|
|
||||||
|
|
||||||
在「设置->第三方插件」中进行插件的安装,点击「社区插件」后面的「浏览」按钮打开插件列表界面进行安装即可。安装插件前,需要先将安全模式的开关关闭。
|
|
||||||
|
|
||||||
### 同步
|
|
||||||
|
|
||||||
安装插件【Remotely Save】,Remotely Save 支持:
|
|
||||||
|
|
||||||
- S3 或兼容S3的服务
|
|
||||||
- Dropbox
|
|
||||||
- Webdav
|
|
||||||
- Onedrive个人版
|
|
||||||
|
|
||||||
最终选择是 Webdav(infinicloud),S3或S3兼容因为paypal账户被限制暂时无法使用,后面可以尝试下。(Cloudflare每个月免费10G的流量看起来还是比infinicloud要香一点)
|
|
||||||
|
|
||||||
WebDav 是非常简单、使用广泛的网盘协议,服务商也非常多。这里推荐 [infinicloud](https://infini-cloud.net/en/),免费层提供 20GB存储,没有其他限制。
|
|
||||||
|
|
||||||
注册后在 My Page 页面打开 Apps Connection,生成 Password,就有了 服务器地址、用户名、密码。
|
|
||||||
|
|
||||||
注意,例如 Remotely Save 里的基文件夹名为 “ROOT”,你要先在 infinicloud 的 File Browser 页面根目录下建立 “ROOT”文件夹。
|
|
||||||
|
|
||||||
infinicloud 是一家日本服务商,在中国访问速度大概 400KB/s~2MB/s,对于笔记这样的大量小文件很够用了。
|
|
||||||
|
|
||||||
#### 为什么不使用坚果云?
|
|
||||||
|
|
||||||
坚果云対用户 webdav api 的调用限制是 500次/30分钟,即使每30分钟同步1次,也会轻易超额报错。
|
|
||||||
|
|
||||||
### 床图
|
|
||||||
|
|
||||||
1. 安装插件【image auto upload】
|
|
||||||
|
|
||||||
2. 安装picgo
|
|
||||||
下面是GitHub的下载点,也可以直接在浏览器搜索picgo。 <https://github.com/Molunerfinn/PicGo/releases/>
|
|
||||||

|
|
||||||
3. github新建仓库
|
|
||||||
|
|
||||||
4. 获取gitbub token, settings->developer settings
|
|
||||||
|
|
||||||
5. 回到picgo,填写github相关内容
|
|
||||||
|
|
||||||
|
|
||||||
### file-explorer-note-count
|
|
||||||
|
|
||||||
用于查看文件夹下文件个数
|
|
||||||
|
|
||||||
### Highlightr
|
|
||||||
|
|
||||||
高亮插件
|
|
||||||
|
|
||||||
### note-refactor
|
|
||||||
|
|
||||||
笔记重构插件,能够让一篇长文,按照指定的分割标志切割成链接引用风格的文章。
|
|
||||||
|
|
||||||
此插件是隐藏功能插件,在我们需要使用的时候,通过调用命令面板进行应用。如下图:
|
|
||||||
如截图所见,我们可以通过选择插件提供的一些切分依据对一篇文章进行打碎重构,比如你的一篇文章标题非常严谨,全部都是通过二级标题作为只是点归类,那么就可以直接选择`Split note by headings - H2`,笔记就会自动基于h2标记对当前文章进行拆分,每个二级标题为一篇文章,笔记新建之后,标题会自动被当前笔记链接,那么一篇完整的笔记,就能够基于二级标题拆分成标准的双链笔记了。
|
|
||||||
|
|
||||||
这款插件可以应用在我们日常写作当中,我们新学习一个知识,在编写笔记的时候不必过多考虑链接之类的概念,只需要在一篇笔记中,利用标题层级做好归类划分,不断完善这个知识点即可,等到觉得差不多的时候,可以利用此插件,一键将一篇笔记拆分成诸多知识点。
|
|
||||||
|
|
||||||
### Editor Syntax Highlight
|
|
||||||
|
|
||||||
提供了在编辑模式中一些代码语法高亮的效果。
|
|
||||||
|
|
||||||
### Tag Wrangler
|
|
||||||
|
|
||||||
- 选项一:更改标签名称
|
|
||||||
可批量更改此标签及其嵌套标签的名称。
|
|
||||||
- 选项二:打开标签页面
|
|
||||||
点击就会自动创建一个带 YAML 语法的笔记,“别名”对应标签名。
|
|
||||||
具体用法稍后介绍。
|
|
||||||
- 选项三:基于标签搜索相关内容
|
|
||||||
- 选项四:搜索不带该标签的其他内容
|
|
||||||
|
|
||||||
除此之外,直接拖拽标签,可将该标签快速插入到文中任意位置。
|
|
||||||
|
|
||||||
### Outliner
|
|
||||||
|
|
||||||
增强大纲
|
|
||||||
|
|
||||||
### Obsidian-text generator
|
|
||||||
|
|
||||||
在 Obsidian 中使用本地 LLM
|
|
||||||
|
|
||||||
### Code block from selection
|
|
||||||
|
|
||||||
将选中的段落设置为代码段,需设置快捷键和默认语言
|
|
||||||
|
|
||||||
### Markdown prettifier
|
|
||||||
|
|
||||||
排版自动美化,设置快捷键为ctrl+s
|
|
||||||
|
|
||||||
### Image Toolkit
|
|
||||||
|
|
||||||
点击图片放大
|
|
||||||
|
|
||||||
### ~~floating -toc~~
|
|
||||||
|
|
||||||
~~悬浮目录~~,不好用,直接使用系统侧栏的目录
|
|
||||||
|
|
||||||
### mousewheel-image-zoom
|
|
||||||
|
|
||||||
鼠标滚动调整图片大小
|
|
||||||
|
|
||||||
### Excalidraw
|
|
||||||
|
|
||||||
流程图,all in one
|
|
||||||
|
|
||||||
字体设置:Excalidraw字体设置
|
|
||||||
|
|
||||||
### 多窗口支持
|
|
||||||
|
|
||||||
Hover Editor
|
|
||||||
|
|
||||||
### 代码块折叠
|
|
||||||
|
|
||||||
Codeblock Customizer
|
|
||||||
@ -1,30 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-12-05 11:27
|
|
||||||
updated: 2024-12-05 11:34
|
|
||||||
tags:
|
|
||||||
- 笔记
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
# 简介
|
|
||||||
|
|
||||||
Quartz 支持 Dataview 的使用,使用简单的 Dataview 语法就能让首页好看一点。Dataview提供了一种类似 SQL 的语法,用于从你的 Markdown 笔记中提取和显示结构化数据。通过 Dataview,你可以创建动态表格、任务列表、图表等,来管理和查询笔记内容。
|
|
||||||
|
|
||||||
# 示例
|
|
||||||
|
|
||||||
使用表格显示所有文件中包含share标签的文件和他的目录
|
|
||||||
|
|
||||||
```text
|
|
||||||
table file.folder as "Directory", file.name as "File Name"
|
|
||||||
from ""
|
|
||||||
where share
|
|
||||||
```
|
|
||||||
|
|
||||||
列出所有tag标签中包含TF-A的文件
|
|
||||||
|
|
||||||
```text
|
|
||||||
list file.name
|
|
||||||
from ""
|
|
||||||
where contains(file.tags, "TF-A")
|
|
||||||
```
|
|
||||||
@ -1,128 +0,0 @@
|
|||||||
---
|
|
||||||
tags:
|
|
||||||
- 笔记
|
|
||||||
- 卡片盒笔记法
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
date: 2024-12-03 11:42
|
|
||||||
updated: 2024-12-03 21:45
|
|
||||||
---
|
|
||||||
|
|
||||||
卢曼的一生硕果累累。在他近 40 年的研究中,出版了 70 多本书和 500 多篇学术文章,内容涵盖法律、经济、政治、艺术、宗教、生态、大众媒体甚至爱情等各个学科,而且他的书并不是胡编乱造,许多都成为各领域的经典之作,也正是这些经典的著作,让卢曼成为 20 世纪最重要的社会理论家之一。
|
|
||||||
卢曼既没有写作困难症,也没有写作焦虑症,许多人都惊叹于卢曼的高产。在他去世前不久,电视台的记者采访卢曼,问及为何能出版这么多的作品时,他将这一切都归功于 Zettelkasten:**Zettelkasten 是他的生产力引擎**。
|
|
||||||
|
|
||||||
> Zettelkasten 是德语,Zettel 是纸条、纸片、卡片的意思,Kasten 是盒子、箱子的意思。Zettelkasten Method 指卡片盒笔记法。
|
|
||||||
|
|
||||||
卢曼的笔记由 90000 多张卡片组成,德国社会学家约翰内斯·F.K.施密特(Johannes F.K. Schmidt)对卢曼的工作流程做了大量研究,他发现,卢曼使用这种独特的归档系统,让他系统地组织了大量学科的读书笔记,为他的理论成果和大量出版物奠定了基础。
|
|
||||||
|
|
||||||
2017 年,一位名叫申克·阿伦斯的德国作家将卢曼做笔记的方法写成了一本书,这本书被迅速被翻译成了各国语言,英文名叫《How to Take Smart Notes》,2021 年 7 月,被翻译成中文《卡片笔记写作法》。Zettelkasten 已经成为一套<mark style="background: #FFB8EBA6;">管理知识的方法论</mark>。一些爱好者甚至成立了专门的网络论坛 ,并开发了课程,教大家如何做笔记。事实上,这套方法是透明的,并没有什么秘密,每个人都能学习,用来管理知识。
|
|
||||||
|
|
||||||
## 我们的笔记系统有什么缺陷?
|
|
||||||
|
|
||||||
几乎每个人都记过笔记,你可能尝试过多种记笔记的方式:
|
|
||||||
|
|
||||||
- 你曾在纸质笔记本上记笔记,
|
|
||||||
- 你曾在书本的空白区域记笔记,
|
|
||||||
- 你曾用手机 APP 来记笔记,
|
|
||||||
- 你曾使用类似微软 Word 这样的文字处理软件来记笔记,
|
|
||||||
- 你画过思维导图,
|
|
||||||
- 或者你在办公桌、显示器上贴满了纸条。
|
|
||||||
|
|
||||||
以上所有方法,都有一个问题:**无法在笔记之间建立连接,<mark style="background: #FFF3A3A6;">无法形成系统</mark>。**
|
|
||||||
|
|
||||||
贴在办公桌上的便签是日抛笔记,用完就丢。记在笔记本上的内容,由于本身装订成册,内容固化在不同位置,就像混凝土中的石头一样,无法灵活重组。而写在书本空白区的阅读心得,会随着阅读结束,一起被放回书架。使用传统的文档软件,也好不到哪去,不一而足。
|
|
||||||
|
|
||||||
那绘制思维导图呢?不得不说,思维导图与卡片盒笔记法比较接近了。思维导图可以建立词条的连接,也能直观地呈现词条之间的关系,但是,它只适合呈现少数内容之间的关系,它无法承载过多的内容,你能想象将卢曼的 90000 条笔记绘制在一张思维导图上的场景吗?
|
|
||||||
|
|
||||||
建立庞大的知识图谱,准确地反映笔记卡片之间的联系,这正是卡片盒笔记法的优势。
|
|
||||||
|
|
||||||
## 卡片盒笔记:为每条笔记分配唯一的编号
|
|
||||||
|
|
||||||
卢曼在写笔记卡片的时候为每一张卡片分配了唯一的编号(ID),编号由数字和字母组合而成,本身不具备任何意义,它的作用是为了方便把独立的卡片连成网状结构。
|
|
||||||
|
|
||||||
日常阅读、思考的过程中,将有价值的内容记下来,在卡片的一角,为卡片添加一个唯一的编号,第一条笔记的编号为 `1`。如果你想添加一条与 `1` 无关的笔记,那么将新笔记编号为 `2`,以此类推。
|
|
||||||
|
|
||||||
如果下一条笔记是对卡片 `2` 内容上的补充,我们以 `2` 为起点**创建分支**,将卡片编号为 `2a`,插入到卡片 `2` 与卡片 `3` 的中间。如果还有一条笔记与 `2` 相关,但与 `2a` 关系不大,那我们将新笔记编号为 `2b`。
|
|
||||||
|
|
||||||
如果又有笔记对 `2a` 进行补充或者评价,那么将新笔记编号为 `2a1`,以此类推。这种用数字和字母间隔的方式对笔记进行编号,能够在内部分支出无限多的序列和子序列。
|
|
||||||
|
|
||||||
|
|
||||||
随着卡片增加,卡片与卡片之间可以建立更复杂的联系。**现实中,知识绝不是孤立存在的,而是互相交织的,只要内容含义上有关联,就可以相互引用。**
|
|
||||||
|
|
||||||
笔记越多,内容越丰富,笔记之间的关联性也越强。按上面 ID 之间的关系,我们将卡片按照下图顺序放在盒子里。
|
|
||||||

|
|
||||||
引入编号系统,带来的好处是:
|
|
||||||
|
|
||||||
1. **方便双向链接**:笔记有了唯一的编号,卡片之间才能互相引用,连接是建立知识图谱不可缺少的功能。
|
|
||||||
2. **笔记可以有机生长(organic growth)**:随着内容不断增多,添加新笔记对过去的内容进行补充变得非常容易——**添加分支**即可,笔记发展的过程,如同树苗成长,从只有几个枝杈长到枝繁叶茂。
|
|
||||||
3. **方便提取笔记**:卡片笔记并没有严格的顺序,笔记互相引用,形式上是种网状结构,这种编号方式,将相关的内容就近收纳,方便提取。
|
|
||||||
|
|
||||||
如果卡片盒里只有 10 或 20 张卡片,迅速找到想要的笔记并不费力。随着笔记越来越多,当笔记的数量超过类似邓巴数的限度时,仅仅依靠记忆、卡片之间的联系,查找笔记将变得非常困难,这时,建立索引就十分必要了。
|
|
||||||
|
|
||||||
## 卡片盒笔记:建立索引
|
|
||||||
|
|
||||||
卢曼的笔记中,有专门用来建立索引的卡片,大致分为两类,**关键词索引**和**主题索引**。
|
|
||||||
|
|
||||||
### 关键词索引
|
|
||||||
|
|
||||||
卡片盒笔记是一个没有固定顺序的系统,寻找特定内容的笔记可能会无从下手,而关键词索引就是为了解决这个问题的。下图是卢曼笔记系统中的一张笔记索引表:
|
|
||||||
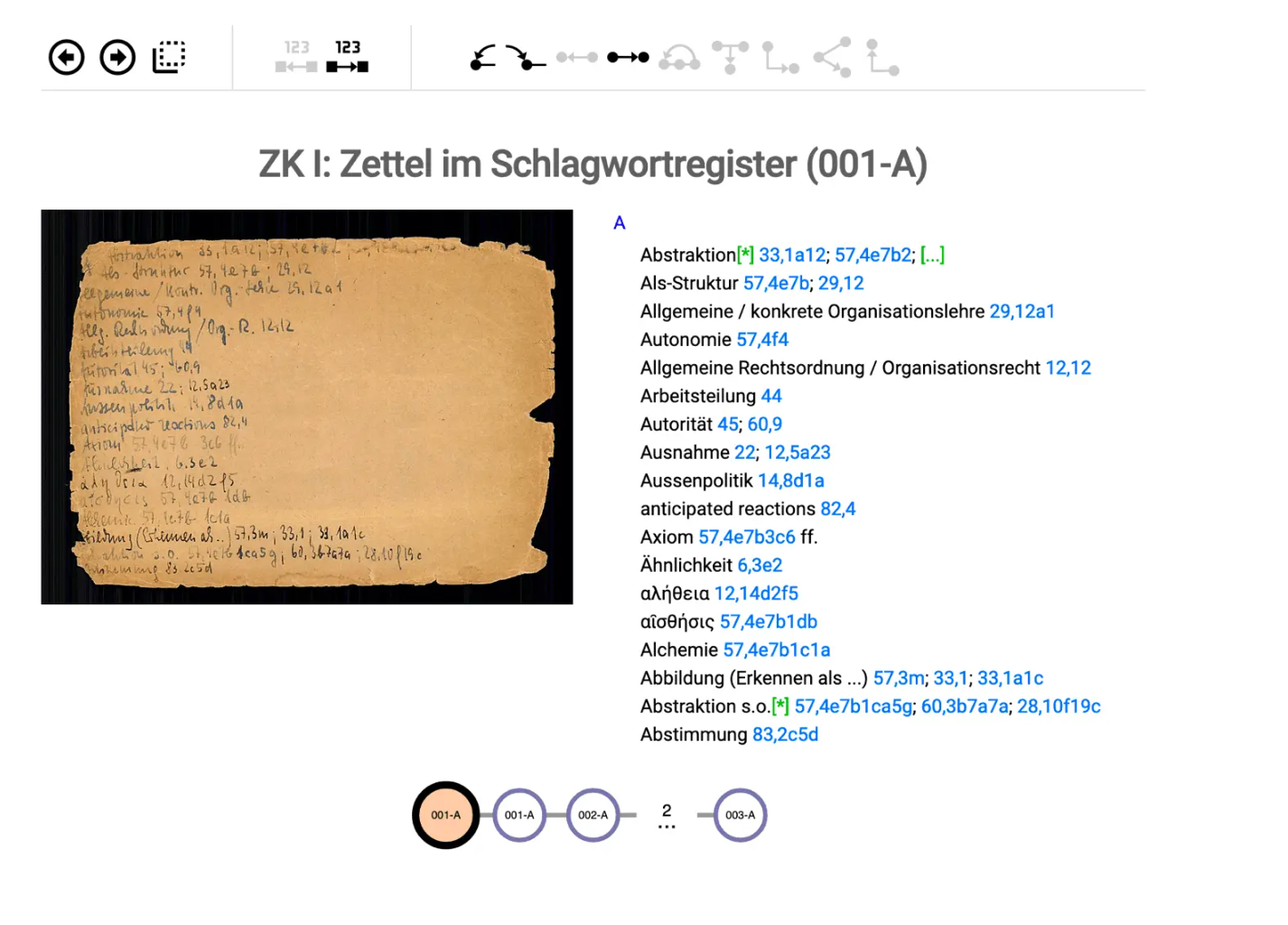
|
|
||||||
功能上类似字典的目录,**关键词索引**是一个纯粹的**入口列表**,每个关键词后面有一个或者几个 ID,入口 ID 所标识的笔记一定是与关键词最紧密相关的。当你找到了入口,就能通过笔记之间互相引用的关系,发现一个更加广阔的知识体系,就像上网时从一个网页跳到另一个网页,有了入口,你就可以在笔记中冲浪了。
|
|
||||||
|
|
||||||
卢曼的笔记系统中,用索引卡片来连接所有笔记是不现实的,也没必要,关键词的索引目的,只是为了快速找到笔记的位置而已。
|
|
||||||
|
|
||||||
### 主题索引
|
|
||||||
|
|
||||||
当一个主题发展到需要概述的程度时,通过收集所有与这个主题相关的内容,用简短的话说明笔记上是什么内容,用一张新的卡片,对主题进行概述,这就是主题索引。这种笔记有助于组织思路,构建项目框架,梳理内容的层次结构,也可以用来构建项目的初稿。整体看来,主题索引更像书籍的目录和概述部分,将分散的内容关联起来,在结构上划分层次,聚合成一个更大的元素。
|
|
||||||
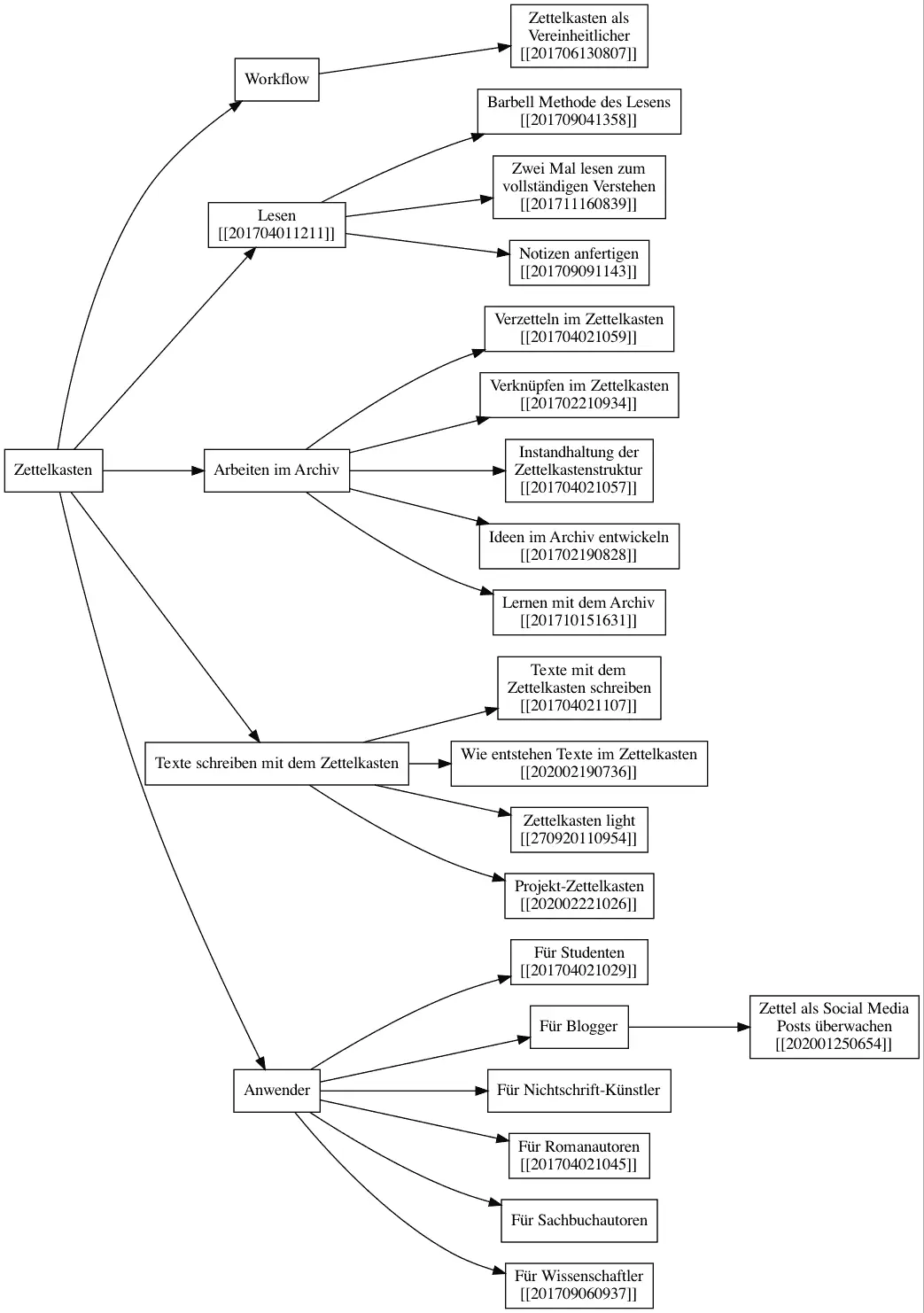
|
|
||||||
|
|
||||||
## 笔记不是简单地收集与分类
|
|
||||||
|
|
||||||
人们倾向于收集大量信息而不对它做任何有用的事情。浏览器收藏夹塞满了各种链接,眼瞅着越塞越多,塞进去就没打开过。买了很多经典书籍,但”买书如山倒,看书如抽丝“。笔记中充满了粘贴复制的内容,甚至都没来得及咀嚼一嚼。下载了学科前沿的论文,保存在文件夹中,但它们很快也被遗忘,沦为数字灰尘。除了制造“读过”、“看过”的幻觉,收集本身不会对大脑产生任何帮助。
|
|
||||||
|
|
||||||
有一个词叫**信息过载**,是指人脑接受太多信息,反而影响正常的理解与决策。人天生喜欢给事物分类,分类能降低大脑负担。我们从小被教导,将玩具和书本放在各自的位置,将外套和内衣收纳在不同的抽屉,自然而然,我们也用同样的策略处理信息。但<mark style="background: #FFB8EBA6;">信息的复杂性可能让你无法找到一个正确的格子放进去,如果将信息强行置于一个“合理的位置”,反而让信息孤立起来,像字典和百科全书一样</mark>。
|
|
||||||
|
|
||||||
笔记系统应该帮助我们消化知识,同时保持面向未来的**弹性**,而不是将信息板结固化。在这一点上,卡片盒笔记做到了。
|
|
||||||
|
|
||||||
## 卡片盒笔记法的优势
|
|
||||||
|
|
||||||
**减轻认知负担**:信息过载,人便无法正常思考。用卡片将信息记下来,当成为大脑卸货,只有脑袋空了,才能更好地思考。
|
|
||||||
|
|
||||||
**帮助消化知识**:很多时候写着写着,想法就通了,因为写写划划本身就是思考的过程。学习新知识时,不妨将自己的认识、心得写下来,用自己的话,描述学到内容。
|
|
||||||
|
|
||||||
**注重连接,而非秩序**:卡片盒笔记的组织方式,似乎缺乏清晰的秩序,它甚至看起来很混乱,然而,这是一个刻意的选择。卡片没有父级、子级的区分,每一张卡片都没有特权。卡片不需要装订,卡片之间通过 ID 互相引用,内容上互相联系,形式上彼此分离,形成了特有的**网络结构**。卡片之间是一种**无序和有序的组合**,任何一张卡片都可以被其他卡片引用,主题卡片又可以对笔记进行归纳整理,这种没有固定秩序的系统,让笔记保持了面向未来的开放性,
|
|
||||||
|
|
||||||
**更符合大脑科学**:罗杰·斯佩里对人脑的研究,揭示了人类大脑的运行机制。左右脑擅长的思维侧重点不同,左半脑擅长排序、逻辑等抽象思维,右半脑擅长艺术、图画、音乐等形象思维。卡片笔记法很好地将线性思维和视觉思维结合起来,结合了左脑和右脑的思维特点,相比传统的笔记方式,卡片笔记法可以同时启动左右两个大脑。
|
|
||||||
|
|
||||||
**功不唐捐**:不管是当下的一点巧思、转瞬即逝的灵感,还是碎片化的阅读心得,抓住它,不要让它溜走。就算笔记无法用于当下正在做的事情,也会成为未来的知识储备,真正用到的时就不必感叹“书到用时方恨少”。
|
|
||||||
|
|
||||||
**从小处着手,提高工作效率**:你一定会遇到大到让你不知从何下手的项目,比如毕业论文,一个课题分享,或者写一本书。面对庞大的项目如同大海捞针——无从下手,不妨退一步,将它拆分成多个小任务。比如每天阅读不同的文献资料,写阅读笔记,最后再将笔记概括起来,一张一张地积累笔记,相比于直接死磕项目,挫败感会小得多。而且从小处着手,也更容易让你进入心流状态,效率更高。
|
|
||||||
|
|
||||||
**形成全面的思维框架**:谚语说“拿着个锤子,看啥都像钉子”,越是认知不够全面的人,思想越容易偏向激进。通过卡片盒,我们能清晰地看到自己过去的想法,不断地去审视过去,总会发现矛盾、悖论和对立。矛盾可能是我们对一个问题思考得不够透彻的标志,或者,应用了不同的思考模式,有了对比才能有改进。
|
|
||||||
|
|
||||||
**更有创造力,让你更好地思考**:卡片盒笔记法让你轻松地在过去的想法和未来的想法之间找到联系,这让 Zettelkasten 成为一种无比强大的创造力工具。创造力不单单是连接想法,所有新颖的创意都是基于已有的想法而成。新卡片与旧卡片建立联系,不同时期的观点碰撞,都会引发新的思考,迸发灵感。
|
|
||||||
|
|
||||||
## 卡片盒笔记的原则
|
|
||||||
|
|
||||||
国外有作者将[卡片盒笔记的使用原则](https://writingcooperative.com/zettelkasten-how-one-german-scholar-was-so-freakishly-productive-997e4e0ca125#:~:text=The%20Zettelkasten%20principles)总结得非常系统,翻译如下:
|
|
||||||
|
|
||||||
1. **原子性原则**:这个词是 [由 Christian Tietze 创造的](https://zettelkasten.de/posts/create-zettel-from-reading-notes/),一个笔记只表述一个内容,这样笔记连接起来的指向性更加明确。
|
|
||||||
2. **自主原则**:每个笔记都应该是独立的,自成一体,包含完整含义,这使得笔记可以独立于相邻位置的卡片进行移动、延伸、分离和串联,就算脱离原始上下文,依然能保证内容的完整性和可读性。
|
|
||||||
3. **始终记得链接你的笔记**:无论何时添加笔记,请确保将其与内容相关的笔记链接,避免断连,正如卢曼本人所说:“每一个笔记都是引用和反向引用系统网络中的一个元素,笔记的质量就是取决于这个网络,没有被链接起来的笔记,将被 Zettelkasten 遗忘。
|
|
||||||
4. [**解释你为什么要链接笔记**](https://zettelkasten.de/posts/zettelkasten-antifragile/):每当你通过链接连接两个笔记时,一定要简要解释你为什么要链接它们。否则,多年后当你重新查看笔记时,你可能忘记连接它们的原因。
|
|
||||||
5. **用你自己的话**:[不要复制和粘贴](https://www.reddit.com/r/Zettelkasten/comments/b566a4/what_is_a_zettelkasten/) 。如果你遇到一个有趣的想法并想将其添加到你的 Zettelkasten 中,你必须用自己的语言表达该想法,确保多年后你还能理解。不要把你的 Zettelkasten 变成一堆复制粘贴的信息。
|
|
||||||
6. **保留参考文献**:[始终在笔记中添加参考文献,以便你知道自己的想法是从哪里获得的](https://www.reddit.com/r/Zettelkasten/comments/b566a4/what_is_a_zettelkasten/) 。这可以防止抄袭,并使你以后可以轻松地重新访问原始来源。
|
|
||||||
7. **将你自己的想法添加到 Zettelkasten**:如果你有自己的想法,请将它们作为笔记添加到 Zettelkasten,同时牢记原子性、自主性和链接需求的原则。
|
|
||||||
8. **不要担心笔记结构**:不要担心将笔记放在整齐的文件夹中,或者按照先入为主的类别进行归类。[正如施密特所说](https://sociologica.unibo.it/article/view/8350/8270),在 Zettelkasten 这张笔记网中,每一个卡片都没有特权地位,也没有顶部也没有底部,让组织有机地发展。
|
|
||||||
9. **添加关联笔记**:当你注意到看似随机的笔记之间的内在关联时,请创建关联笔记,该笔记的目的是将其它笔记链接在一起并解释它们之间的关系。
|
|
||||||
10. **添加大纲笔记**:随着想法开始合并为主题,创建大纲笔记。大纲笔记是只包含一系列指向其他笔记的链接的笔记,将其他笔记按特定顺序排列以创建故事、叙述或论点。(主题索引)
|
|
||||||
11. **从不删除**:不要删除旧笔记,相反,链接到一条新的笔记去解释旧笔记有什么问题。这样,[你的 Zettelkasten 将反映你的思维是如何随着时间的推移而演变的](https://sociologica.unibo.it/article/view/8350/8270),这将防止 [事后偏见](https://rationalwiki.org/wiki/Hindsight_bias)。此外,如果你不删除,你可能会重新审视那些可能最终证明是正确的旧想法。
|
|
||||||
12. **大胆添加笔记**:你的 Zettelkasten 中永远不会被信息塞满,而且,你将添加那些不会立即使用的笔记。就算添加更多笔记也不会破坏你的 Zettelkasten ,或干扰其正常运行。要知道,卢曼在他的 Zettelkasten 中有 90,000 条笔记!
|
|
||||||
|
|
||||||
## 让笔记成为生产力引擎
|
|
||||||
|
|
||||||
江郎才尽的规律不适用于卢曼,近 40 年的职业生涯,始终保持着“文思如泉涌”的状态,甚至在他去世后,人们将他办公室里快完成的手稿整理出来,又有六七本有关宗教、教育、政治等不同主题的书以他的署名出版。
|
|
||||||
|
|
||||||
卢曼的卡片盒蕴藏着巨大的生命力,卢曼曾用不同的方式描述他的笔记系统,有时称它为 [**谈话伙伴**](https://zettelkasten.de/introduction/zh/) ,有时将它描述为 [**第二存储器**、**控制论系统**、**反刍动物**或**化粪池**](https://www.uni-bielefeld.de/soz/luhmann-archiv/pdf/jschmidt_zettelkasten-als-uberraschungsgenerator.pdf) 。
|
|
||||||
|
|
||||||
卢曼的学术生涯,都围绕卡片盒展开,卡片盒不仅用来吸收知识、存储知识、消化知识,更重要的是它帮助卢曼产生洞见和灵感,它是思想结晶的地方。这就是为什么说,卡片盒笔记不是信息工具,而是思维工具,是知识管理的方法论,更是一套智识生产的架构。
|
|
||||||
@ -1,183 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2025-01-21 09:50
|
|
||||||
updated: 2025-02-14 14:21
|
|
||||||
link: "false"
|
|
||||||
share: "true"
|
|
||||||
---
|
|
||||||
|
|
||||||
# 下载代码
|
|
||||||
|
|
||||||
```sh
|
|
||||||
git clone https://github.com/citrineos/citrineos-core
|
|
||||||
```
|
|
||||||
|
|
||||||
# citrineos-operator-ui
|
|
||||||
|
|
||||||
使用npm直接安装时,directus无法使用时安装的,用docker不需要这个步骤,直接访问8055端口。
|
|
||||||
|
|
||||||
## rabbitmq-server
|
|
||||||
|
|
||||||
### 安装
|
|
||||||
|
|
||||||
```sh
|
|
||||||
sudo apt-get install -y rabbitmq-server
|
|
||||||
```
|
|
||||||
|
|
||||||
### 打开
|
|
||||||
|
|
||||||
```sh
|
|
||||||
sudo systemctl start rabbitmq-server
|
|
||||||
```
|
|
||||||
|
|
||||||
## PostgreSQL
|
|
||||||
|
|
||||||
### 安装
|
|
||||||
|
|
||||||
还要下载postgis插件。。不提前说,太傻逼了。
|
|
||||||
|
|
||||||
```sh
|
|
||||||
sudo apt-get install postgresql-17
|
|
||||||
sudo apt install postgis
|
|
||||||
sudo apt install postgresql-17-postgis-3
|
|
||||||
```
|
|
||||||
|
|
||||||
### 打开
|
|
||||||
|
|
||||||
```sh
|
|
||||||
sudo systemctl enable --now postgresql
|
|
||||||
```
|
|
||||||
|
|
||||||
### 查看状态
|
|
||||||
|
|
||||||
```sh
|
|
||||||
# wyq @ wangyq in ~/citrineos-core/Server on git:main x [10:20:16]
|
|
||||||
$ sudo systemctl status postgresql
|
|
||||||
● postgresql.service - PostgreSQL RDBMS
|
|
||||||
Loaded: loaded (/usr/lib/systemd/system/postgresql.service; enabled; preset: disabled)
|
|
||||||
Active: active (exited) since Tue 2025-01-21 09:55:35 CST; 25s ago
|
|
||||||
Invocation: 7b2162ad244c43e9bad1b180eee3092b
|
|
||||||
Process: 17635 ExecStart=/bin/true (code=exited, status=0/SUCCESS)
|
|
||||||
Main PID: 17635 (code=exited, status=0/SUCCESS)
|
|
||||||
|
|
||||||
Jan 21 09:55:35 wangyq systemd[1]: Starting postgresql.service - PostgreSQL RDBMS...
|
|
||||||
Jan 21 09:55:35 wangyq systemd[1]: Finished postgresql.service - PostgreSQL RDBMS.
|
|
||||||
```
|
|
||||||
|
|
||||||
### 创建账户
|
|
||||||
|
|
||||||
```sh
|
|
||||||
# wyq @ wangyq in ~/citrineos-core/Server on git:main x [10:42:56] C:1
|
|
||||||
$ sudo -i -u postgres
|
|
||||||
┏━(Message from Kali developers)
|
|
||||||
┃
|
|
||||||
┃ This is a minimal installation of Kali Linux, you likely
|
|
||||||
┃ want to install supplementary tools. Learn how:
|
|
||||||
┃ ⇒ https://www.kali.org/docs/troubleshooting/common-minimum-setup/
|
|
||||||
┃
|
|
||||||
┗━(Run: “touch ~/.hushlogin” to hide this message)
|
|
||||||
postgres@wangyq:~$ psql
|
|
||||||
psql (17.2 (Debian 17.2-1), server 16.3 (Debian 16.3-1+b1))
|
|
||||||
Type "help" for help.
|
|
||||||
|
|
||||||
postgres=# CREATE USER citrine WITH PASSWORD 'citrine';
|
|
||||||
CREATE ROLE
|
|
||||||
postgres=# CREATE DATABASE citrine owner citrine;
|
|
||||||
CREATE DATABASE
|
|
||||||
postgres=# GRANT ALL PRIVILEGES ON DATABASE citrine TO citrine;
|
|
||||||
GRANT
|
|
||||||
postgres=# \c citrine;
|
|
||||||
You are now connected to database "citrine" as user "postgres".
|
|
||||||
citrine=# CREATE EXTENSION postgis;
|
|
||||||
CREATE EXTENSION
|
|
||||||
```
|
|
||||||
|
|
||||||
# 使用
|
|
||||||
|
|
||||||
## citrineos-operator-ui
|
|
||||||
|
|
||||||
```sh
|
|
||||||
# wyq @ wangyq in ~/citrineos/citrineos-core-1.5.0/Server [15:57:06]
|
|
||||||
$ docker compose up -d
|
|
||||||
[+] Running 4/4
|
|
||||||
⠿ Container server-ocpp-db-1 Healthy 7.1s
|
|
||||||
⠿ Container server-amqp-broker-1 Healthy 11.6s
|
|
||||||
⠿ Container server-directus-1 Healthy 17.0s
|
|
||||||
⠿ Container server-citrine-1 Started 17.4s
|
|
||||||
|
|
||||||
# wyq @ wangyq in ~/citrineos/citrineos-core-1.5.0/Server [15:57:26]
|
|
||||||
$ docker compose up -d graphql-engine data-connector-agent
|
|
||||||
no such service: graphql-engine
|
|
||||||
|
|
||||||
# wyq @ wangyq in ~/citrineos/citrineos-core-1.5.0/Server [15:57:41] C:1
|
|
||||||
$ cd ../citrineos-operator-ui/
|
|
||||||
|
|
||||||
# wyq @ wangyq in ~/citrineos/citrineos-core-1.5.0/citrineos-operator-ui on git:main x [15:57:52]
|
|
||||||
$ docker compose up -d graphql-engine data-connector-agent
|
|
||||||
[+] Running 2/2
|
|
||||||
⠿ Container citrineos-operator-ui-data-connector-agent-1 Healthy 5.8s
|
|
||||||
⠿ Container citrineos-operator-ui-graphql-engine-1 S... 6.2s
|
|
||||||
|
|
||||||
# wyq @ wangyq in ~/citrineos/citrineos-core-1.5.0/citrineos-operator-ui on git:main x [15:58:00]
|
|
||||||
$ npm run dev
|
|
||||||
|
|
||||||
> citrineos-refine@0.1.0 dev
|
|
||||||
> refine dev
|
|
||||||
|
|
||||||
╭─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
|
|
||||||
│ │
|
|
||||||
│ — Refine Devtools beta version is out! To install in your project, just run npm run refine devtools init. │
|
|
||||||
│ https://s.refine.dev/devtools-beta │
|
|
||||||
│ │
|
|
||||||
│ — Hello from Refine team! Hope you enjoy! Join our Discord community to get help and discuss with other users. │
|
|
||||||
│ https://discord.gg/refine │
|
|
||||||
│ │
|
|
||||||
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
|
|
||||||
|
|
||||||
✗ Refine Devtools server (http) failed to start. Port 5001 is already in use.
|
|
||||||
|
|
||||||
ℹ You can change the port by setting the REFINE_DEVTOOLS_PORT environment variable.
|
|
||||||
|
|
||||||
✗ Refine Devtools server (websocket) failed to start. Port 5001 is already in use.
|
|
||||||
|
|
||||||
Port 5173 is in use, trying another one...
|
|
||||||
|
|
||||||
VITE v4.5.5 ready in 372 ms
|
|
||||||
|
|
||||||
➜ Local: http://localhost:5174/
|
|
||||||
➜ Network: use --host to expose
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
## EVerest
|
|
||||||
|
|
||||||
### 拉取代码
|
|
||||||
|
|
||||||
```sh
|
|
||||||
git clone https://github.com/EVerest/everest-demo.git
|
|
||||||
cd everest-demo
|
|
||||||
```
|
|
||||||
|
|
||||||
### 添加充电桩
|
|
||||||
|
|
||||||
```sh
|
|
||||||
./citrineos/add-charger.sh
|
|
||||||
```
|
|
||||||
|
|
||||||
### 开启模拟
|
|
||||||
|
|
||||||
```sh
|
|
||||||
bash demo-ac.sh -c -1
|
|
||||||
```
|
|
||||||
|
|
||||||
-c:使用citrineos
|
|
||||||
-1:profile 1
|
|
||||||
|
|
||||||
## 查看log
|
|
||||||
|
|
||||||
```sh
|
|
||||||
docker cp everest-ac-demo-manager-1:/tmp/everest_ocpp_logs /mnt/d/
|
|
||||||
```
|
|
||||||
|
|
||||||
## 发送指令
|
|
||||||
|
|
||||||
感觉需要二次封装,拜拜不看了
|
|
||||||
@ -1,90 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-11-25 16:10
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
updated: 2024-12-03 21:46
|
|
||||||
---
|
|
||||||
|
|
||||||
# 方法一、仅使用于烧写过版本板子,新板子不适用
|
|
||||||
|
|
||||||
uboot下tftp烧写 (以太网接eth2) ,需要PC有tftp服务器
|
|
||||||
|
|
||||||
启机进uboot 看到Autoboot in 3 seconds字样狂按ctrl +c
|
|
||||||
|
|
||||||
```sh
|
|
||||||
Boot over spi-nand0!
|
|
||||||
STM32MP> <INTERRUPT>
|
|
||||||
STM32MP> <INTERRUPT>
|
|
||||||
STM32MP> <INTERRUPT>
|
|
||||||
STM32MP>
|
|
||||||
STM32MP>
|
|
||||||
STM32MP>
|
|
||||||
STM32MP>
|
|
||||||
STM32MP> setenv ipaddr 192.168.137.109
|
|
||||||
STM32MP>ping 192.168.137.53
|
|
||||||
```
|
|
||||||
|
|
||||||
如果提示没有网口,需要设置下
|
|
||||||
|
|
||||||
```sh
|
|
||||||
setenv ethaddr 10:e7:7a:e1:a2:96
|
|
||||||
```
|
|
||||||
|
|
||||||
ping通提示alive就开始烧写
|
|
||||||
|
|
||||||
```sh
|
|
||||||
STM32MP> tftpboot 0xd0000000 192.168.137.53:rootfs.ubi
|
|
||||||
Using eth1@5800a000 device
|
|
||||||
TFTP from server 192.168.137.53; our IP address is 192.168.137.109
|
|
||||||
Filename 'rootfs.ubi'.
|
|
||||||
Load address: 0xd0000000
|
|
||||||
Loading: ################################################# 107 MiB
|
|
||||||
2.5 MiB/s
|
|
||||||
done
|
|
||||||
Bytes transferred = 112197632 (6b00000 hex)
|
|
||||||
|
|
||||||
STM32MP> mtd erase UBI
|
|
||||||
Erasing 0x00000000 ... 0x1eefffff (1980 eraseblock(s))
|
|
||||||
Skipping bad block at 0x02900000
|
|
||||||
Skipping bad block at 0x05680000
|
|
||||||
Skipping bad block at 0x08400000
|
|
||||||
Skipping bad block at 0x0b180000
|
|
||||||
Skipping bad block at 0x0df00000
|
|
||||||
Skipping bad block at 0x10c80000
|
|
||||||
Skipping bad block at 0x13a00000
|
|
||||||
Skipping bad block at 0x16780000
|
|
||||||
Skipping bad block at 0x19500000
|
|
||||||
Skipping bad block at 0x1c280000
|
|
||||||
STM32MP> mtd write UBI 0xd0000000 0X0 0x6b00000 ##0X6b00000是包的大小 tftpboot命令结束会提示hex大小
|
|
||||||
Writing 112197632 byte(s) (27392 page(s)) at offset 0x00000000
|
|
||||||
STM32MP> reset
|
|
||||||
```
|
|
||||||
|
|
||||||
# 方法二、适用于任何板子
|
|
||||||
|
|
||||||
1. 需要接飞线接USB,~~让硬件帮忙飞下~~,改版后直接接烧写小板。
|
|
||||||
|
|
||||||
2. 去stm32官网下载安装STM32CubeProgrammer
|
|
||||||
<https://www.st.com/en/development-tools/stm32cubeprog.html#get-software>
|
|
||||||
|
|
||||||
3. usb接入电脑,新板子要接串口,3个boot脚短接
|
|
||||||

|
|
||||||
|
|
||||||
打开软件 ,port 选择加入的USB, connect
|
|
||||||
|
|
||||||
|
|
||||||
选择对应版本下的tsv文件
|
|
||||||
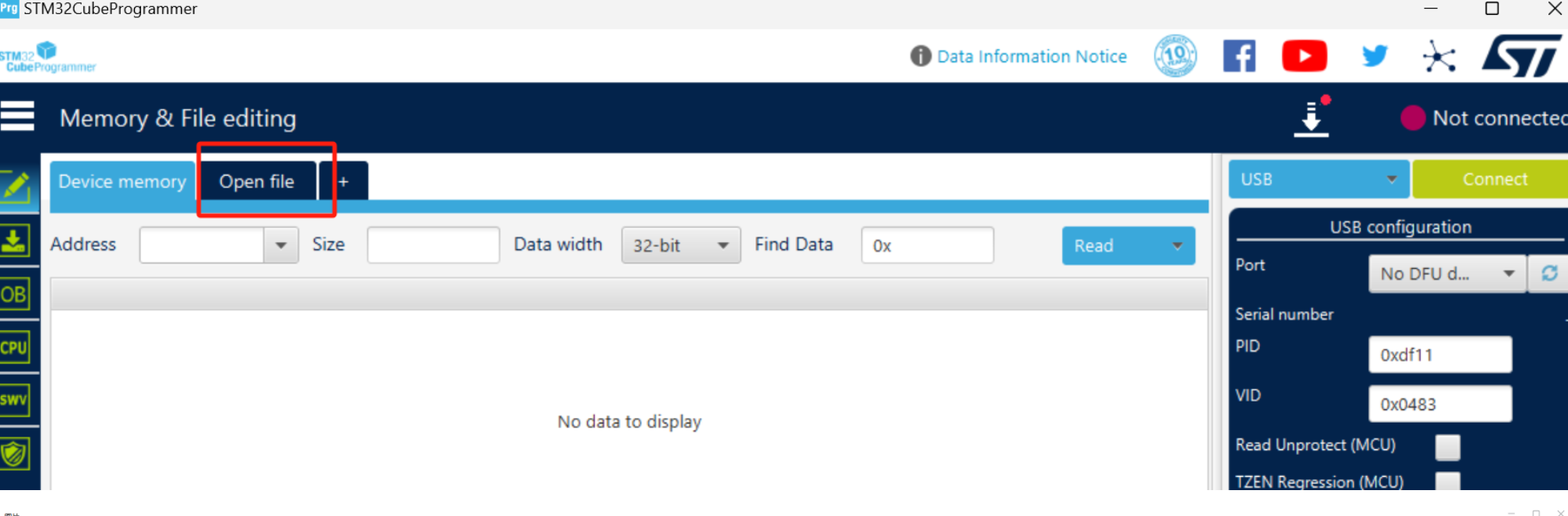
|
|
||||||
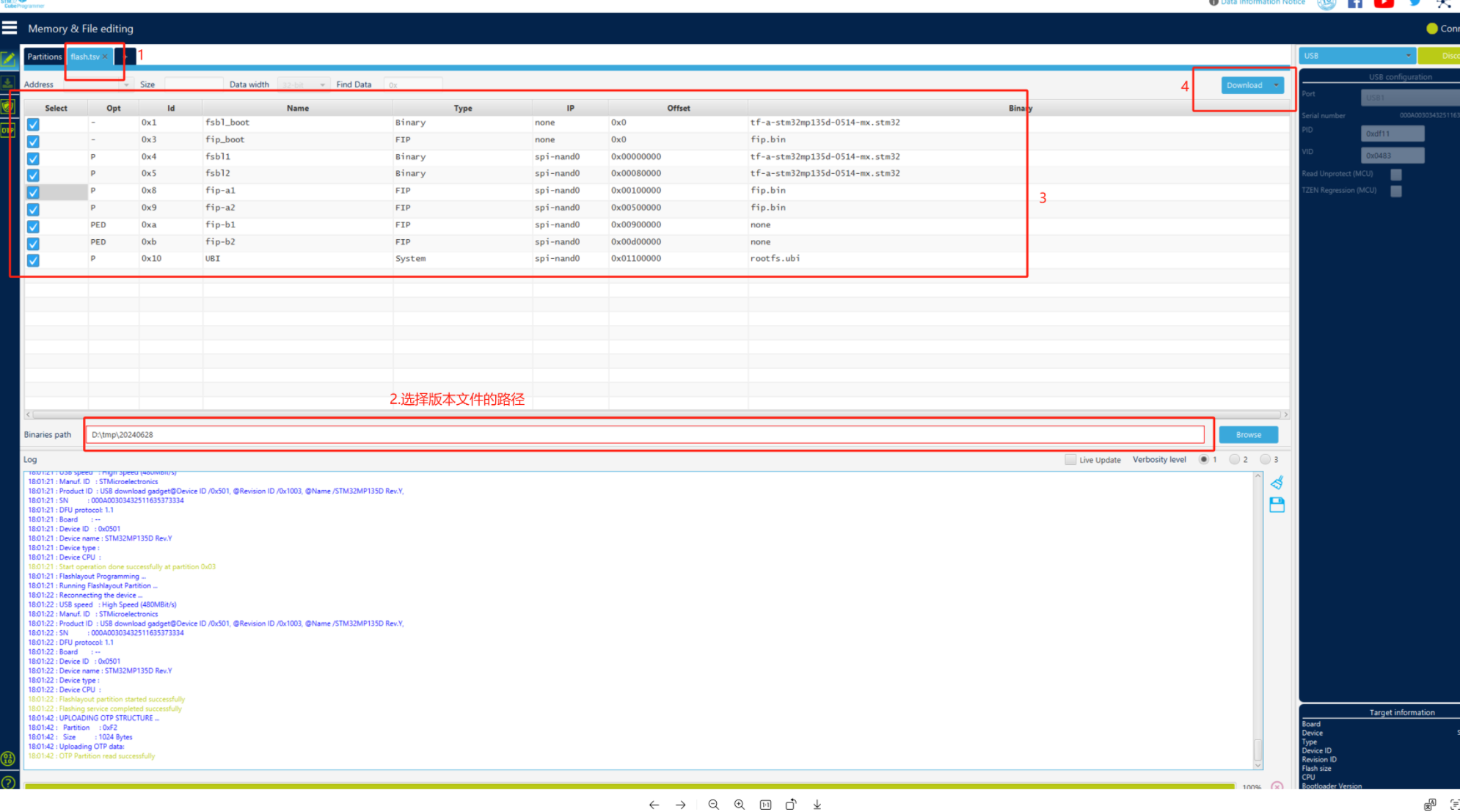
|
|
||||||
**旧版子烧写完重启就行了**
|
|
||||||
|
|
||||||
**仅新板子烧写需要,不是新板子不要进行下面的操作,**
|
|
||||||
|
|
||||||
```sh
|
|
||||||
# 升级完成后打开串口按ctrl +c
|
|
||||||
STM32MP> <INTERRUPT>
|
|
||||||
STM32MP> fuse prog -y 0 9 20400000
|
|
||||||
Programming bank 0 word 0x00000009 to 0x20400000...
|
|
||||||
STM32MP> reset
|
|
||||||
resetting ...
|
|
||||||
```
|
|
||||||
@ -1,94 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-10-31 16:48
|
|
||||||
updated: 2024-12-03 21:44
|
|
||||||
tags:
|
|
||||||
- 设计模式
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
# 什么是DAO?
|
|
||||||
|
|
||||||
**DAO** (Data Access Object数据访问对象)是一个设计模式,用于==处理程序与数据源之间的交互==。数据源可以是数据库、文件系统或其他存储系统。DAO的主要作用是将业务逻辑(你的应用程序的主要功能)与数据访问逻辑(如何存取数据)分开。
|
|
||||||
|
|
||||||
# 为什么要使用DAO?
|
|
||||||
|
|
||||||
## 分离关注点
|
|
||||||
|
|
||||||
将业务逻辑与数据访问逻辑分开,使代码更加清晰和易于维护。你可以专注于实现业务功能,而不必关心如何存取数据。
|
|
||||||
|
|
||||||
## 方便更改
|
|
||||||
|
|
||||||
如果需要更换数据源(例如,从MySQL换成PostgreSQL),只需修改DAO的实现,不用更改业务逻辑。
|
|
||||||
|
|
||||||
## 提高可测试性
|
|
||||||
|
|
||||||
使用DAO模式,你可以创建模拟对象来测试业务逻辑,而无需连接真实的数据库。这**使得单元测试更加简单和高效**。
|
|
||||||
|
|
||||||
# DAO的组成部分
|
|
||||||
|
|
||||||
一个典型的DAO结构通常包括以下几个部分:
|
|
||||||
|
|
||||||
## DAO接口
|
|
||||||
|
|
||||||
定义数据访问的方法,例如:
|
|
||||||
|
|
||||||
```java
|
|
||||||
public interface UserDAO {
|
|
||||||
void create(User user);
|
|
||||||
User read(int id);
|
|
||||||
void update(User user);
|
|
||||||
void delete(int id);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
## DAO实现类
|
|
||||||
|
|
||||||
实现上述接口,并包含具体的数据访问逻辑。例如,使用[[../编程语言/Java/JDBC|JDBC]]来连接数据库:
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class UserDAOImpl implements UserDAO {
|
|
||||||
@Override
|
|
||||||
public void create(User user) {
|
|
||||||
// 代码来插入用户到数据库
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public User read(int id) {
|
|
||||||
// 代码来从数据库读取用户
|
|
||||||
return user;
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public void update(User user) {
|
|
||||||
// 代码来更新用户信息
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public void delete(int id) {
|
|
||||||
// 代码来删除用户
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
## 业务逻辑层
|
|
||||||
|
|
||||||
调用DAO接口来执行操作。它不需要知道具体的实现细节:
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class UserService {
|
|
||||||
private UserDAO userDAO;
|
|
||||||
|
|
||||||
public UserService(UserDAO userDAO) {
|
|
||||||
this.userDAO = userDAO;
|
|
||||||
}
|
|
||||||
|
|
||||||
public void registerUser(User user) {
|
|
||||||
userDAO.create(user);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
# 总结
|
|
||||||
|
|
||||||
DAO模式的核心思想是通过一个抽象层(DAO接口)与具体实现(DAO实现类)分离数据访问逻辑,使得代码更加模块化和可维护。理解这一模式能更好地构建应用程序,并能在以后的项目中更灵活地处理数据。
|
|
||||||
@ -1,24 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-10-31 17:03
|
|
||||||
updated: 2024-12-03 21:44
|
|
||||||
tags:
|
|
||||||
- 设计模式
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
MVC 是“模型-视图-控制器”(Model-View-Controller)的缩写,是一种设计模式,常用于构建用户界面和管理应用程序的结构。它将应用程序分为三个主要组件:
|
|
||||||
|
|
||||||
1. **模型(Model)**:负责管理数据和业务逻辑。它代表应用程序的核心功能,与数据存储和处理有关。
|
|
||||||
|
|
||||||
2. **视图(View)**:负责显示数据(即模型)给用户。视图通常包括用户界面元素,如按钮、文本框等。
|
|
||||||
|
|
||||||
3. **控制器(Controller)**:作为模型和视图之间的中介。它接收用户输入(如点击按钮或填写表单),并根据输入更新模型或视图。
|
|
||||||
|
|
||||||
MVC 的优点包括:
|
|
||||||
|
|
||||||
- **分离关注点**:将应用程序的不同部分分开,便于管理和维护。
|
|
||||||
- **重用性**:可以在不改变模型或控制器的情况下替换视图。
|
|
||||||
- **可测试性**:因为组件分离,可以更容易地对各个部分进行单元测试。
|
|
||||||
|
|
||||||
这种模式广泛应用于网页开发、桌面应用程序以及移动应用程序的开发中。
|
|
||||||
@ -1,17 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-10-31 17:00
|
|
||||||
updated: 2024-12-03 21:44
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
ORM(对象关系映射,Object-Relational Mapping)框架是一种用于==将对象编程语言中的对象与关系型数据库中的数据表进行映射的工具==。它通过提供一个抽象层,使开发者能够以面向对象的方式操作数据库,而无需直接编写SQL语句。
|
|
||||||
|
|
||||||
ORM框架的主要功能包括:
|
|
||||||
|
|
||||||
1. **对象映射**:将数据库表映射为类,将表中的行映射为对象。
|
|
||||||
2. **查询生成**:自动生成SQL查询,简化数据库操作。
|
|
||||||
3. **数据管理**:提供增删改查等常用操作的简化接口。
|
|
||||||
4. **事务管理**:处理数据库事务,确保数据一致性。
|
|
||||||
|
|
||||||
常见的ORM框架有Hibernate(Java)、Entity Framework(.NET)、Django ORM(Python)等。使用ORM可以提高开发效率,减少重复代码,并且更易于维护。
|
|
||||||
@ -1,188 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-10-29 11:28
|
|
||||||
updated: 2024-12-03 21:44
|
|
||||||
tags:
|
|
||||||
- 设计模式
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
# 概述
|
|
||||||
|
|
||||||
## 什么是依赖注入
|
|
||||||
|
|
||||||
**依赖注入**的核心思想是==将对象的依赖关系从类内部移到外部管理==。也就是说,**不是由类自己来创建它所依赖的对象,而是将这些依赖通过构造函数参数、方法参数或属性设置的方式传递给它**。这样,类不再负责依赖的创建和管理,而是依赖于外部注入,这样可以更方便地替换或修改依赖对象。
|
|
||||||
|
|
||||||
## 控制反转(Inversion of Control, IoC)
|
|
||||||
|
|
||||||
依赖注入是==控制反转(IoC)的一种实现方式==。IoC 是一种设计原则,指的是将对象的控制权从内部转移到外部。依赖注入通过构造函数、方法或属性注入的方式,实现了 IoC。
|
|
||||||
|
|
||||||
## 依赖注入的好处
|
|
||||||
|
|
||||||
- **低耦合度**:减少对象之间的直接依赖,提高代码的灵活性。
|
|
||||||
- **易于测试**:可以方便地替换依赖对象,进行单元测试。
|
|
||||||
- **高可维护性**:通过集中管理依赖,便于维护和扩展。
|
|
||||||
|
|
||||||
## 依赖注入的类型
|
|
||||||
|
|
||||||
依赖注入主要有以下几种方式:
|
|
||||||
|
|
||||||
- **构造函数注入(Constructor Injection)**:通过构造函数传递依赖。
|
|
||||||
|
|
||||||
- **方法注入(Method Injection)**:通过方法参数传递依赖。
|
|
||||||
|
|
||||||
- **属性注入(Property Injection)**:通过设置结构体的字段来传递依赖。
|
|
||||||
|
|
||||||
# 依赖注入解决了什么问题
|
|
||||||
|
|
||||||
## 硬编码的依赖
|
|
||||||
|
|
||||||
如果 `UserService` 自己创建了 `UserRepository`,就像这样:
|
|
||||||
|
|
||||||
```go
|
|
||||||
type UserService struct {
|
|
||||||
repo *DatabaseUserRepository
|
|
||||||
}
|
|
||||||
|
|
||||||
func NewUserService() *UserService {
|
|
||||||
return &UserService{
|
|
||||||
repo: &DatabaseUserRepository{}, // 硬编码依赖
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
这里的问题是:`UserService`**紧密依赖于**`DatabaseUserRepository`。如果你想要使用不同的 `UserRepository` 实现(例如,改成 `InMemoryUserRepository` 进行测试),就不得不修改 `UserService` 结构体中 `repo` 字段类型了。这种耦合降低了代码的灵活性和可测试性。
|
|
||||||
|
|
||||||
## 依赖注入的本质
|
|
||||||
|
|
||||||
依赖注入的精髓是将**对象所依赖的其他对象**从**类的内部**移到**类的外部**,并由外部来管理这些依赖。换句话说,**对象不再负责创建它的依赖,而是由外部传入这些依赖**。
|
|
||||||
|
|
||||||
```c
|
|
||||||
type UserService struct {
|
|
||||||
repo UserRepository // 依赖于接口,而不是具体实现
|
|
||||||
}
|
|
||||||
|
|
||||||
func NewUserService(repo UserRepository) *UserService {
|
|
||||||
return &UserService{repo: repo} // 依赖由外部传入
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
通过这种方式:
|
|
||||||
|
|
||||||
- `UserService` 不再依赖于特定的 `UserRepository` 实现,它只依赖于 `UserRepository` 接口。
|
|
||||||
- 依赖的具体实现(如 `DatabaseUserRepository` 或 `InMemoryUserRepository`)可以在运行时由外部决定,并通过构造函数传入。这就是**依赖注入**。
|
|
||||||
|
|
||||||
# C语言中的依赖注入
|
|
||||||
|
|
||||||
C语言本身并不直接支持依赖注入模式,因为它没有内置的面向对象编程特性,如C++或Java中的类和接口。然而,可以==通过结构体和函数指针来模拟依赖注入的概念==。
|
|
||||||
|
|
||||||
以下是一个简单的依赖注入示例,使用结构体和函数指针来定义依赖和提供注入点:
|
|
||||||
|
|
||||||
```c
|
|
||||||
#include <stdio.h>
|
|
||||||
#include <stdlib.h>
|
|
||||||
|
|
||||||
// 定义依赖接口
|
|
||||||
typedef struct {
|
|
||||||
void (*print_message)(const char *message);
|
|
||||||
} Dependency;
|
|
||||||
|
|
||||||
// 依赖的实现
|
|
||||||
void print_message(const char *message) {
|
|
||||||
printf("%s\n", message);
|
|
||||||
}
|
|
||||||
|
|
||||||
// 使用依赖的函数
|
|
||||||
void use_dependency(Dependency *dependency) {
|
|
||||||
dependency->print_message("Hello, Dependency!");
|
|
||||||
}
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
// 创建依赖实例
|
|
||||||
Dependency dependency;
|
|
||||||
dependency.print_message = print_message;
|
|
||||||
|
|
||||||
// 使用依赖
|
|
||||||
use_dependency(&dependency);
|
|
||||||
|
|
||||||
return 0;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
在这个例子中,`Dependency` 结构体定义了一个打印消息的==函数指针==。`print_message` 函数实现了这个接口。`use_dependency` 函数接受一个`Dependency`结构体指针作为参数,并调用其`print_message`方法。在`main`函数中,我们创建了一个`Dependency`实例并设置了它的`print_message`方法指针指向`print_message`函数的实现。
|
|
||||||
|
|
||||||
这个例子展示了如何在不修改`use_dependency`函数代码的情况下,通过结构体和函数指针来动态注入依赖。虽然这不是面向对象编程中的依赖注入,但在C语言中可以通过这种方式模拟依赖注入。
|
|
||||||
|
|
||||||
# C++简单实现依赖注入
|
|
||||||
|
|
||||||
在C++中实现依赖注入的一种简单方式是使用工厂模式和配置文件。以下是一个简单的例子:
|
|
||||||
|
|
||||||
```c++
|
|
||||||
#include <iostream>
|
|
||||||
#include <map>
|
|
||||||
#include <string>
|
|
||||||
#include <memory>
|
|
||||||
|
|
||||||
// 抽象基类
|
|
||||||
class BaseClass {
|
|
||||||
public:
|
|
||||||
virtual void Show() = 0;
|
|
||||||
virtual ~BaseClass() = default;
|
|
||||||
};
|
|
||||||
|
|
||||||
// 实现类A
|
|
||||||
class ClassA : public BaseClass {
|
|
||||||
public:
|
|
||||||
void Show() override {
|
|
||||||
std::cout << "Class A" << std::endl;
|
|
||||||
}
|
|
||||||
};
|
|
||||||
|
|
||||||
// 实现类B
|
|
||||||
class ClassB : public BaseClass {
|
|
||||||
public:
|
|
||||||
void Show() override {
|
|
||||||
std::cout << "Class B" << std::endl;
|
|
||||||
}
|
|
||||||
};
|
|
||||||
|
|
||||||
// 工厂类
|
|
||||||
class Factory {
|
|
||||||
public:
|
|
||||||
BaseClass* Create(const std::string& type) {
|
|
||||||
if (creators.find(type) != creators.end()) {
|
|
||||||
return creators[type]();
|
|
||||||
}
|
|
||||||
return nullptr;
|
|
||||||
}
|
|
||||||
|
|
||||||
void Register(const std::string& type, std::function<BaseClass*()> creator) {
|
|
||||||
creators[type] = creator;
|
|
||||||
}
|
|
||||||
|
|
||||||
private:
|
|
||||||
std::map<std::string, std::function<BaseClass*()>> creators;
|
|
||||||
};
|
|
||||||
|
|
||||||
// 使用工厂
|
|
||||||
int main() {
|
|
||||||
Factory factory;
|
|
||||||
|
|
||||||
// 注册类
|
|
||||||
factory.Register("A", []() { return new ClassA(); });
|
|
||||||
factory.Register("B", []() { return new ClassB(); });
|
|
||||||
|
|
||||||
// 创建对象
|
|
||||||
BaseClass* obj = factory.Create("A");
|
|
||||||
if (obj) {
|
|
||||||
obj->Show();
|
|
||||||
delete obj;
|
|
||||||
}
|
|
||||||
|
|
||||||
return 0;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
这段代码定义了一个基类`BaseClass`和两个实现类`ClassA`和`ClassB`。`Factory`类负责创建对象,通过`Register`方法将类型与创建对象的函数绑定,通过`Create`方法根据类型创建对象。
|
|
||||||
|
|
||||||
在`main`函数中,我们注册了两个实现类,并根据提供的类型字符串创建了一个对象。这个例子展示了依赖注入的简单实现,但在实际应用中可能需要考虑内存管理、多线程和异常处理等问题。
|
|
||||||
@ -1,90 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-10-31 16:55
|
|
||||||
updated: 2024-12-03 21:44
|
|
||||||
tags:
|
|
||||||
- java
|
|
||||||
- 数据库
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
**JDBC**(Java Database Connectivity)是Java语言中的一套API,用于与各种数据库进行交互。它提供了一种标准的方法来连接、查询、更新和管理数据库中的数据。以下是一些关于JDBC的基本概念和功能:
|
|
||||||
|
|
||||||
### 主要功能
|
|
||||||
|
|
||||||
1. **连接数据库**:JDBC允许Java应用程序与数据库建立连接。通过提供数据库的URL、用户名和密码,可以连接到特定的数据库实例。
|
|
||||||
|
|
||||||
2. **执行SQL语句**:一旦建立连接,JDBC可以执行SQL查询(例如`SELECT`)、插入(`INSERT`)、更新(`UPDATE`)和删除(`DELETE`)等操作。
|
|
||||||
|
|
||||||
3. **处理结果**:执行SQL语句后,JDBC会返回结果集(ResultSet),你可以通过它读取查询结果。
|
|
||||||
|
|
||||||
4. **事务管理**:JDBC支持事务操作,可以通过commit和rollback来管理数据库的状态。
|
|
||||||
|
|
||||||
### JDBC的组成部分
|
|
||||||
|
|
||||||
1. **JDBC驱动**:驱动是连接特定数据库的实现,负责处理与数据库的实际交互。根据不同的数据库类型,有不同的JDBC驱动(例如,MySQL、PostgreSQL、Oracle等)。驱动通常有四种类型:
|
|
||||||
- **类型 1**:JDBC-ODBC桥接驱动(不推荐使用)
|
|
||||||
- **类型 2**:本地API驱动
|
|
||||||
- **类型 3**:网络协议驱动
|
|
||||||
- **类型 4**:纯Java驱动(推荐使用,通常是最常用的)
|
|
||||||
|
|
||||||
2. **Connection**:表示与数据库的连接,可以用来创建Statement对象。
|
|
||||||
|
|
||||||
3. **Statement**:用于执行SQL语句的对象,有几种不同的类型:
|
|
||||||
- `Statement`:用于执行简单的SQL语句。
|
|
||||||
- `PreparedStatement`:用于执行预编译的SQL语句,更高效且可防止SQL注入。
|
|
||||||
- `CallableStatement`:用于执行存储过程。
|
|
||||||
|
|
||||||
4. **ResultSet**:表示查询结果的数据集,允许遍历结果集中的记录。
|
|
||||||
|
|
||||||
### 基本使用示例
|
|
||||||
|
|
||||||
下面是一个简单的JDBC示例,展示如何连接到数据库并执行查询:
|
|
||||||
|
|
||||||
```java
|
|
||||||
import java.sql.Connection;
|
|
||||||
import java.sql.DriverManager;
|
|
||||||
import java.sql.ResultSet;
|
|
||||||
import java.sql.Statement;
|
|
||||||
|
|
||||||
public class JdbcExample {
|
|
||||||
public static void main(String[] args) {
|
|
||||||
String url = "jdbc:mysql://localhost:3306/your_database";
|
|
||||||
String user = "your_username";
|
|
||||||
String password = "your_password";
|
|
||||||
|
|
||||||
try {
|
|
||||||
// 1. 加载驱动
|
|
||||||
Class.forName("com.mysql.cj.jdbc.Driver");
|
|
||||||
|
|
||||||
// 2. 建立连接
|
|
||||||
Connection connection = DriverManager.getConnection(url, user, password);
|
|
||||||
|
|
||||||
// 3. 创建Statement
|
|
||||||
Statement statement = connection.createStatement();
|
|
||||||
|
|
||||||
// 4. 执行查询
|
|
||||||
String sql = "SELECT * FROM users";
|
|
||||||
ResultSet resultSet = statement.executeQuery(sql);
|
|
||||||
|
|
||||||
// 5. 处理结果
|
|
||||||
while (resultSet.next()) {
|
|
||||||
System.out.println("User ID: " + resultSet.getInt("id"));
|
|
||||||
System.out.println("Username: " + resultSet.getString("username"));
|
|
||||||
}
|
|
||||||
|
|
||||||
// 6. 关闭连接
|
|
||||||
resultSet.close();
|
|
||||||
statement.close();
|
|
||||||
connection.close();
|
|
||||||
|
|
||||||
} catch (Exception e) {
|
|
||||||
e.printStackTrace();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### 总结
|
|
||||||
|
|
||||||
JDBC是Java程序与数据库交互的重要工具,它提供了统一的接口来处理不同数据库的操作,使得Java开发者能够轻松地执行数据库相关的任务。
|
|
||||||
@ -1,132 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-08-15 17:30
|
|
||||||
updated: 2024-12-03 21:44
|
|
||||||
tags:
|
|
||||||
- BUG
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
# 过程
|
|
||||||
|
|
||||||
MCP使用以太网连接平台,长时间挂机后会提示HAL_ETH_GetDMAError错误。
|
|
||||||
使用wireshark抓包,可以发现以太网有像桩端发送数据,但是没有收到应答。
|
|
||||||
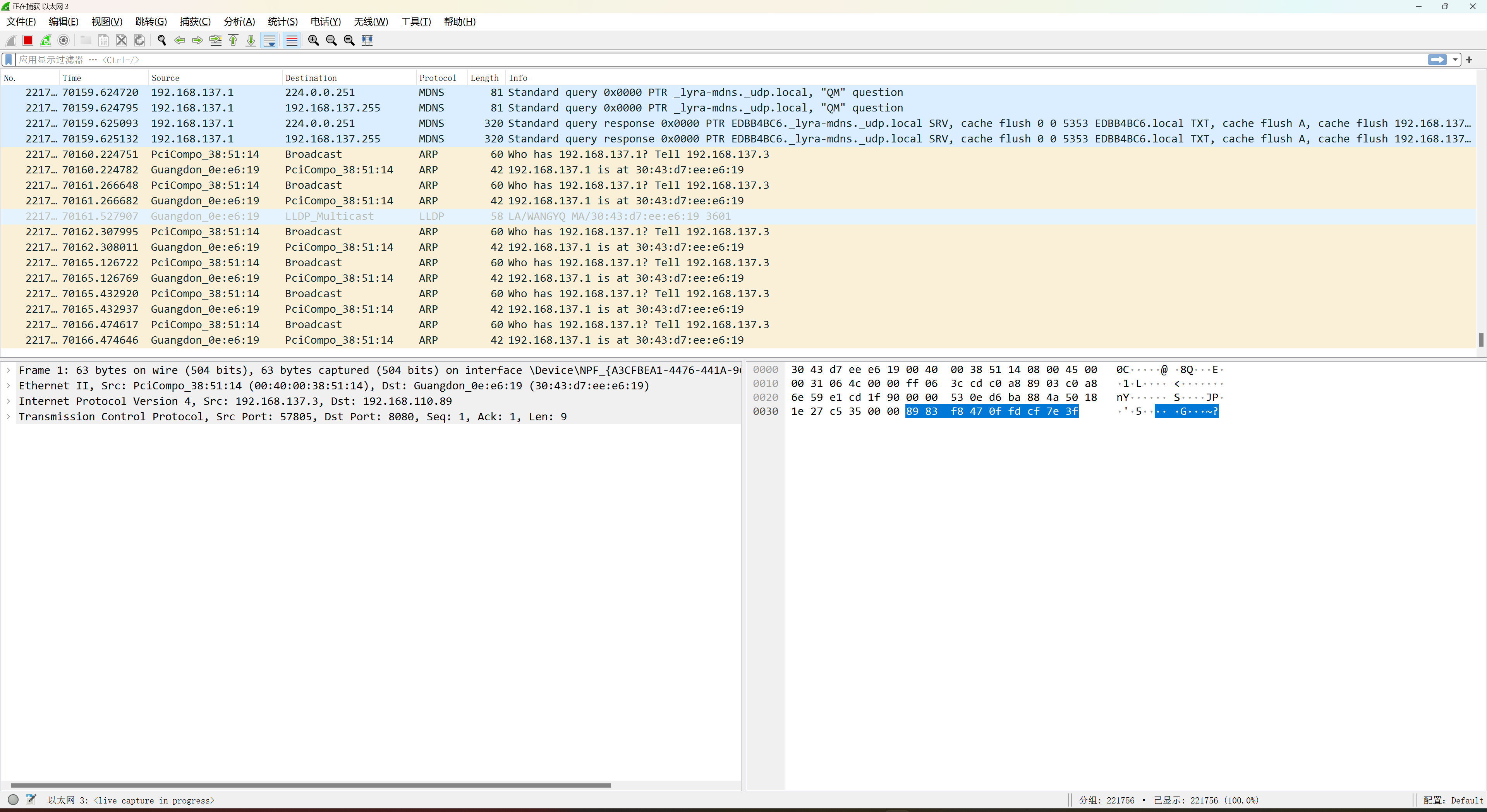
|
|
||||||
ping网关,可以看到网关有接收到桩端发送的ARP请求,并且有应答,但是桩没有接收到报文。
|
|
||||||
|
|
||||||
在[ST论坛](https://community.st.com/t5/stm32-mcus-embedded-software/eth-dmacsr-rbu-error-occurs-and-stalls-the-ethernet-receive-on/m-p/124038)看到一样的问题,解决办法是在HAL_ETH_ErrorCallback中断回调中去清除寄存器。
|
|
||||||
|
|
||||||
```c
|
|
||||||
void HAL_ETH_ErrorCallback(ETH_HandleTypeDef *heth)
|
|
||||||
{
|
|
||||||
if((HAL_ETH_GetDMAError(heth) & ETH_DMACSR_RBU) == ETH_DMACSR_RBU)
|
|
||||||
{
|
|
||||||
printf( "ETH DMA Rx Error\n" );
|
|
||||||
osSemaphoreRelease(RxPktSemaphore);
|
|
||||||
// Clear RBUS ETHERNET DMA flag
|
|
||||||
heth->Instance->DMACSR = ETH_DMACSR_RBU;
|
|
||||||
// Resume DMA reception
|
|
||||||
heth->Instance->DMACRDTPR = 0;
|
|
||||||
}
|
|
||||||
if((HAL_ETH_GetDMAError(heth) & ETH_DMACSR_TBU) == ETH_DMACSR_TBU)
|
|
||||||
{
|
|
||||||
printf( "ETH DMA Tx Error\n" );
|
|
||||||
osSemaphoreRelease(TxPktSemaphore);
|
|
||||||
//Clear TBU flag to resume processing
|
|
||||||
heth->Instance->DMACSR = ETH_DMACSR_TBU;
|
|
||||||
//Instruct the DMA to poll the transmit descriptor list
|
|
||||||
heth->Instance->DMACTDTPR = 0;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
以及在上层的LWIP中修改tcp接收窗口,这个没有用,查看LWIP的值一直都是他修复后的数值。
|
|
||||||
|
|
||||||
尝试了上面的方法后发现没有什么作用。选择先规避这个问题,在上面的ERROR中断回调中增加以太网的重新初始化。
|
|
||||||
|
|
||||||
```c
|
|
||||||
if((HAL_ETH_GetDMAError(heth) & ETH_DMACSR_TBU) == ETH_DMACSR_TBU)
|
|
||||||
{
|
|
||||||
printf( "ETH DMA Tx Error\n" );
|
|
||||||
osSemaphoreRelease(TxPktSemaphore);
|
|
||||||
//Clear TBU flag to resume processing
|
|
||||||
heth->Instance->DMACSR = ETH_DMACSR_TBU;
|
|
||||||
//Instruct the DMA to poll the transmit descriptor list
|
|
||||||
heth->Instance->DMACTDTPR = 0;
|
|
||||||
HAL_ETH_DeInit(&EthHandle);
|
|
||||||
HAL_ETH_Init(&EthHandle);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
测试了下,虽然会导致websocket连接断掉,但是可以接受。但是测试使用以太网升级固件的时候,因为数据量大,产生错包的概率增加,重新初始化后又进入了RX ERROR中,导致无限重新初始化。
|
|
||||||
|
|
||||||
然后再ST的github上搜索ETH_DMACSR_RBU,找到了一个[已解决的方案](https://github.com/STMicroelectronics/STM32CubeH7/issues/222#issuecomment-1159086674),就是把上面的清除的动作放到rx的while线程中执行,RX ERROR 中断中不执行任何操作。
|
|
||||||
|
|
||||||
```c
|
|
||||||
void HAL_ETH_ErrorCallback(ETH_HandleTypeDef *heth)
|
|
||||||
{
|
|
||||||
if((HAL_ETH_GetDMAError(heth) & ETH_DMACSR_RBU) == ETH_DMACSR_RBU)
|
|
||||||
{
|
|
||||||
osSemaphoreRelease(RxPktSemaphore);
|
|
||||||
}
|
|
||||||
if((HAL_ETH_GetDMAError(heth) & ETH_DMACSR_TBU) == ETH_DMACSR_TBU)
|
|
||||||
{
|
|
||||||
osSemaphoreRelease(TxPktSemaphore);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
static void ethernet_watchdog(void) {
|
|
||||||
if ((ETH->DMACSR & ETH_DMACSR_RBU) == ETH_DMACSR_RBU )
|
|
||||||
{
|
|
||||||
// Clear RBUS ETHERNET DMA flag
|
|
||||||
ETH->DMACSR = ETH_DMACSR_RBU;
|
|
||||||
// Resume DMA reception
|
|
||||||
ETH->DMACRDTPR = 0;
|
|
||||||
}
|
|
||||||
if ((ETH->DMACSR & ETH_DMACSR_TBU) == ETH_DMACSR_TBU )
|
|
||||||
{
|
|
||||||
// Clear RBUS ETHERNET DMA flag
|
|
||||||
ETH->DMACSR = ETH_DMACSR_TBU;
|
|
||||||
// Resume DMA reception
|
|
||||||
ETH->DMACTDTPR = 0;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
void ethernetif_input( void * pvParameters )
|
|
||||||
{
|
|
||||||
struct pbuf *p;
|
|
||||||
|
|
||||||
for( ;; )
|
|
||||||
{
|
|
||||||
. . .
|
|
||||||
ethernet_watchdog();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
此时,测试上面的使用以太网升级固件的问题,发现可以升级成功。但是挂测了一段时间后发现又回到了原点,进入RX ERROR后,以太网又无法使用了。
|
|
||||||
|
|
||||||
再ethernet_watchdog函数中添加打印,发现以太网的状态分为3个阶段,第一个阶段是正常的使用,第二个阶段是ETH_DMACSR_RBU被置位,然后又被DMA看门狗清除,不断的重复这个过程,但是此时的以太网是可以使用的。第三个阶段是进入了RX ERROR的回调中,以太网彻底无法使用。
|
|
||||||
|
|
||||||
在ST的官方论坛中,有[类似的现象](https://community.st.com/t5/stm32-mcus-embedded-software/unmodified-stm32h723-lwip-http-server-socket-rtos-example-gets/m-p/696179),上面没有确切的解决办法,call fae问原厂拿解决方法。
|
|
||||||
|
|
||||||
> 把stm32h7xx_hal_eth.c文件中的一段代码:
|
|
||||||
> tailidx = (descidx + 1U) % ETH_RX_DESC_CNT;
|
|
||||||
> 改成:
|
|
||||||
> tailidx = (ETH_RX_DESC_CNT + descidx - 1U) % ETH_RX_DESC_CNT;
|
|
||||||
> 目的是将tail pointer指向前一个描述符,而不是后一个描述符。
|
|
||||||
> 说这样有助于更好地提高效率和阻止丢包。
|
|
||||||
|
|
||||||
在H5中找到类似的函数,将描述符从后一个改为前一个后,发现这个改动会产生死机
|
|
||||||
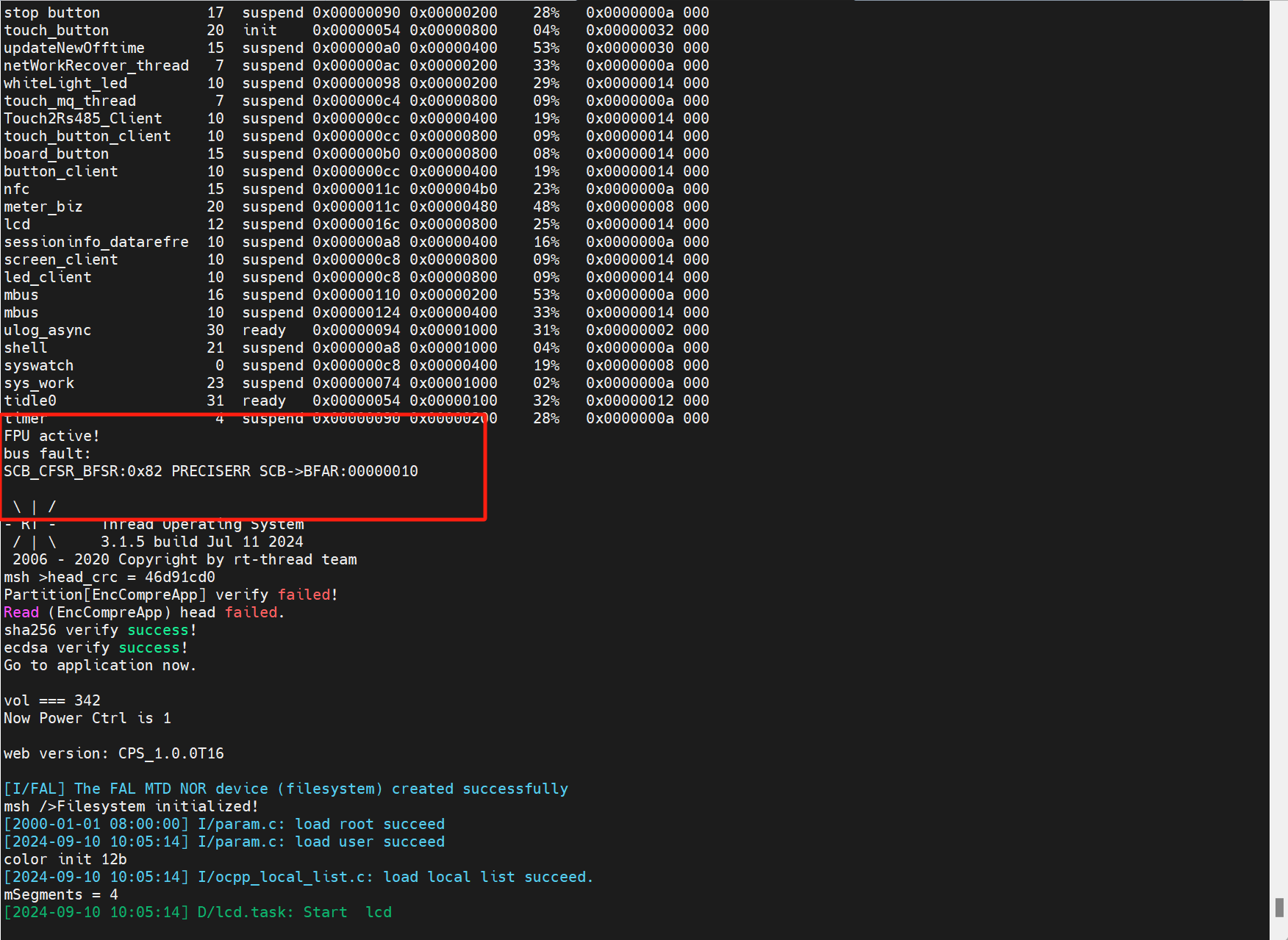
|
|
||||||
|
|
||||||
因为上面的思路是提高以太网的效率,之前都是想解决RX ERROR产生的DMA Buffer被占用完的问题,于是打开DCACHE,想提高以太网的效率,看能否产生一样的效果。
|
|
||||||
|
|
||||||
打开DCACHE后,挂测一天,发现虽然还是会产生ETH_DMACSR_RBU的情况,但是可以自恢复,且多数情况下不会与平台断联。
|
|
||||||
|
|
||||||
但是并没有完全解决这个问题,ST论坛的出了关于h5解决上面的那个问题的方法了,和fae给出的方法是一样的。。这说明我的hal库和官方现有的不一致,更新hal库,挂测2天发现问题解决了。
|
|
||||||
|
|
||||||
# 总结
|
|
||||||
|
|
||||||
- 尽量不要使用STM32CubeMX生成的代码,直接去github上找新的代码。在fae给我他的解决方案的时候,我是有怀疑过hal库不是最新的,还重新用STM32CubeMX生成一遍后和原有的代码比较。没想到的是他的源就不是最新,只能怀疑是h5和h7的写法不同。不然这个问题应该很早就能解决。STM32CubeMX只适合拿来入门,真正要拿来工程使用的还是得自己搭建。
|
|
||||||
- 对以太网底层的原理理解得不深刻,不能只依赖hal库的修复,太过被动了。后续有时间得过下hal库的以太网代码,增加理解。
|
|
||||||
@ -1,192 +0,0 @@
|
|||||||
---
|
|
||||||
date: 2024-11-28 10:54
|
|
||||||
updated: 2024-12-03 11:57
|
|
||||||
tags:
|
|
||||||
- BUG
|
|
||||||
- mbedtls
|
|
||||||
share: "true"
|
|
||||||
link: "false"
|
|
||||||
---
|
|
||||||
|
|
||||||
# 解决过程
|
|
||||||
|
|
||||||
## MBEDTLS_SSL_VERIFY_NONE
|
|
||||||
|
|
||||||
客户平台使用自签名的证书导致无法连接。按正常的思路将服务器的证书校验关闭就可以了。如下在连接中将参数设置为`MBEDTLS_SSL_VERIFY_NONE`
|
|
||||||
|
|
||||||
```c
|
|
||||||
mbedtls_ssl_conf_authmode(&session->conf, MBEDTLS_SSL_VERIFY_NONE);
|
|
||||||
```
|
|
||||||
|
|
||||||
但是很奇怪的事情发生了,经过测试发现上面的设置好像没有什么帮助。使用wireshark抓包可以看到,提示证书损坏。
|
|
||||||

|
|
||||||
|
|
||||||
## LIBRWS_USING_MBED_TLS
|
|
||||||
|
|
||||||
既然已经关闭证书校验了,为什么还会去验证证书呢。看了使用的rws库发现了宏`LIBRWS_USING_MBED_TLS`没有使用,于是怀疑是因为rws库没有关联mbedtls导致mbedtls中的证书校验关了,但是rws使用了另外的接口又去验证了平台的证书。打开这个宏发现编译报错,因为迭代了太多次导致这个宏无法使用了。于是继续从rws的`connect`函数进入,发现rws的`connect`关联到了`sal_connect`。
|
|
||||||
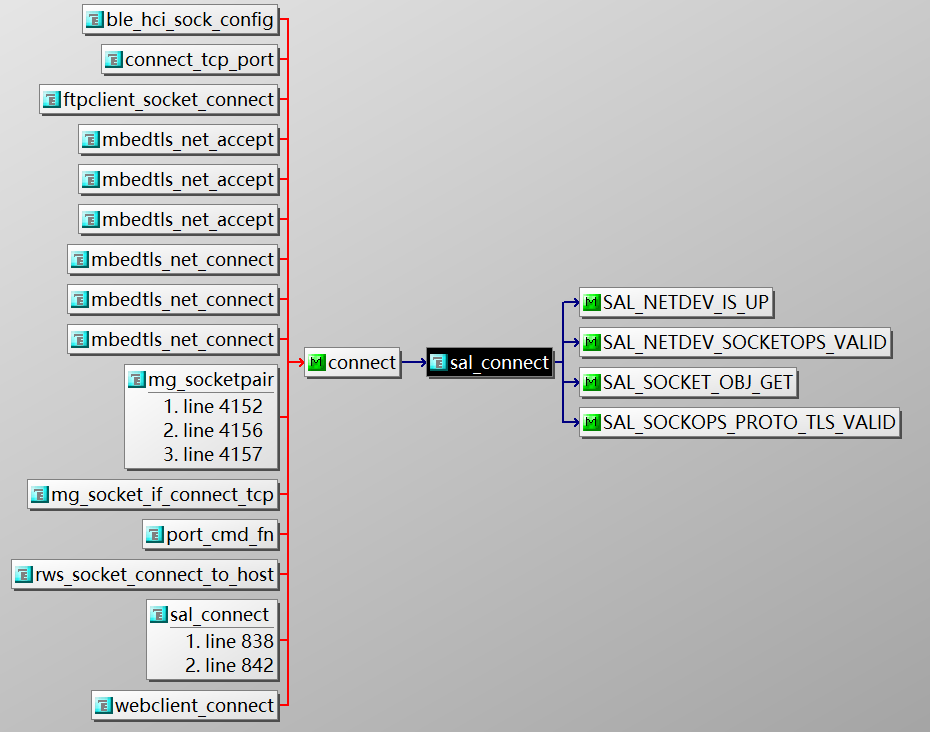
|
|
||||||
而sal_connect又注册了mbedtls的connect接口。
|
|
||||||
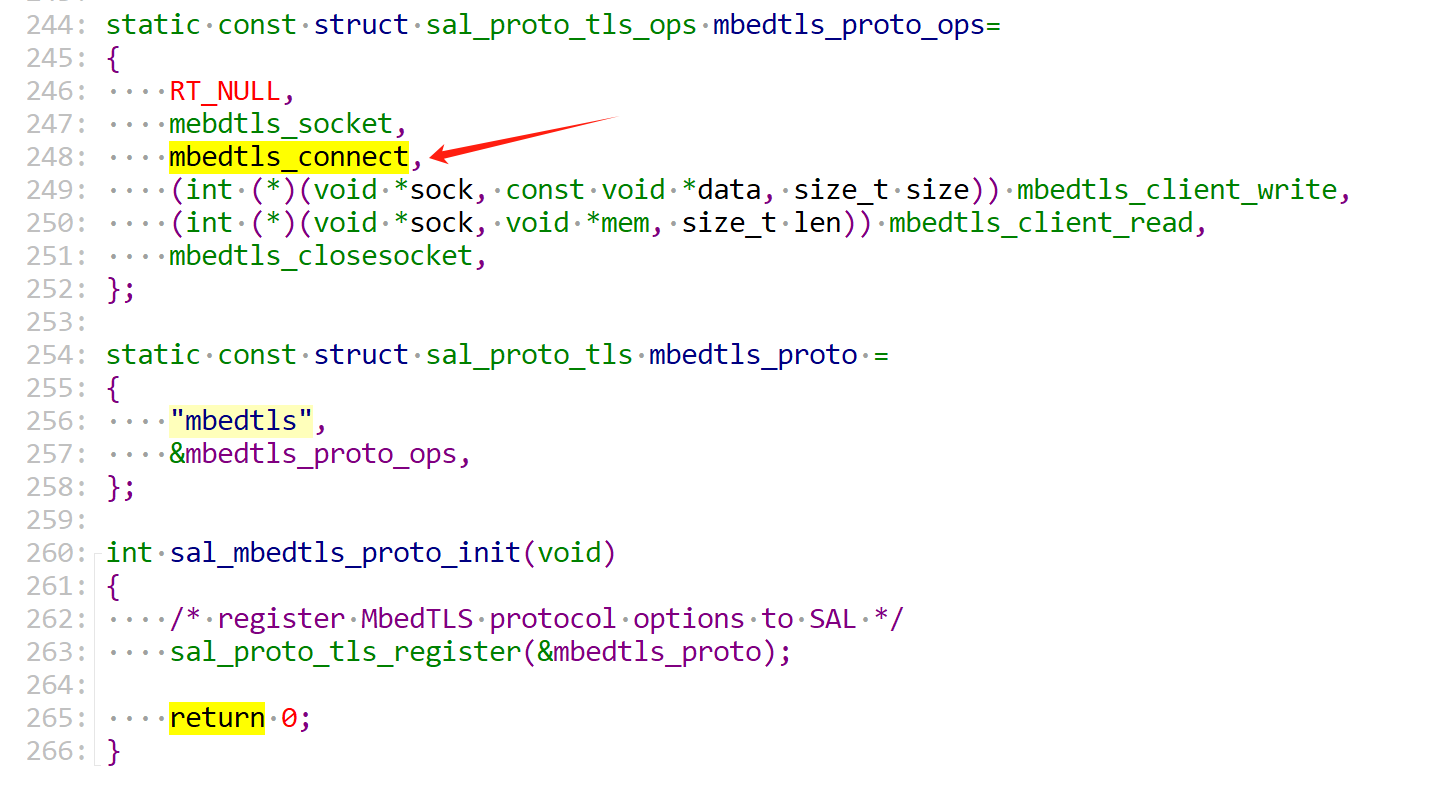
|
|
||||||
所以说饶了一圈又回到了原来的地方,`LIBRWS_USING_MBED_TLS`的开关并不影响wss的连接。
|
|
||||||
|
|
||||||
## MBEDTLS_SSL_ALERT_MSG_BAD_CERT
|
|
||||||
|
|
||||||
抓包的bad certificate 对应mbedtls中的的宏`MBEDTLS_SSL_ALERT_MSG_BAD_CERT`,这个宏在项目中只有在一下两个地方有使用到。
|
|
||||||

|
|
||||||
往上层找,可以看到这个两个函数都是在`mbedtls_ssl_parse_certificate`中被调用的,他的上层函数`mbedtls_ssl_handshake_client_step`是tls层中客户端的交互流程,`mbedtls_ssl_parse_certificate`本身则是ServerHello后的Certificate步骤。
|
|
||||||
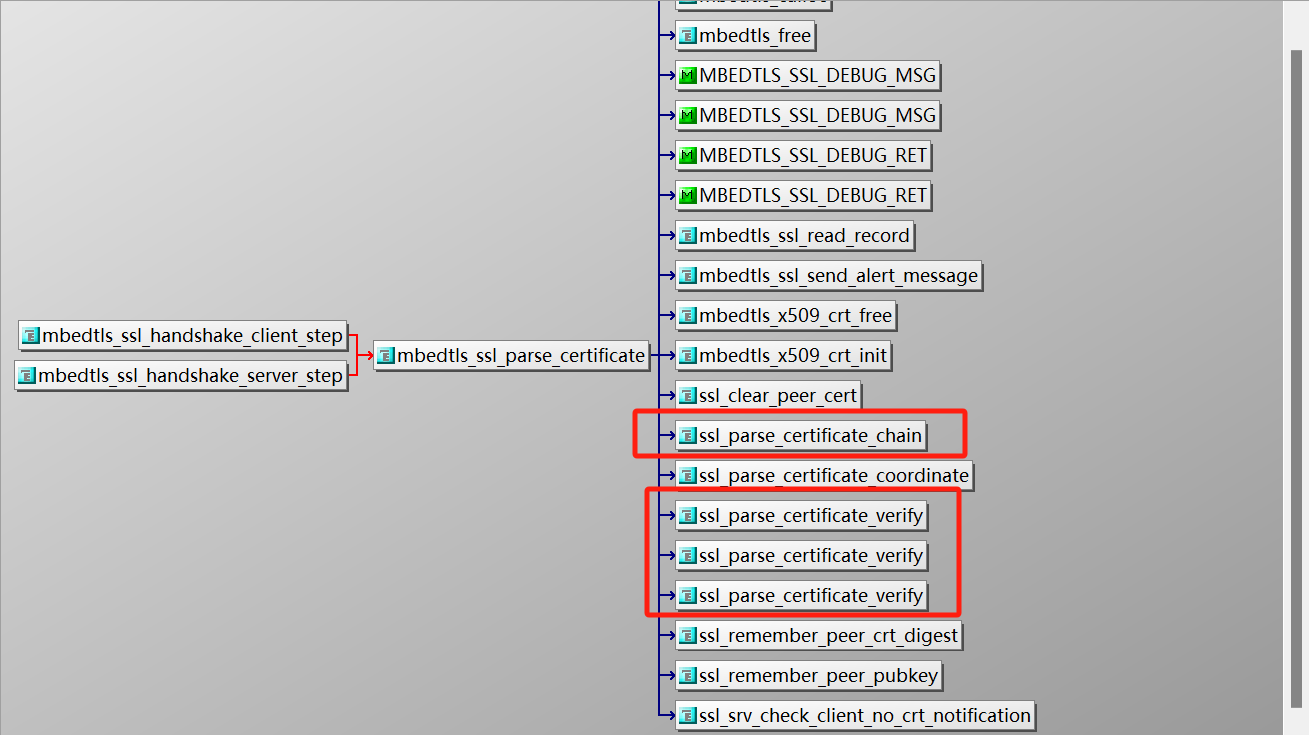
|
|
||||||
观察这个函数可以看到他是有对`authmode`这个参数做处理的,这个参数就是上面的[[客户平台无法连接问题#MBEDTLS_SSL_VERIFY_NONE|MBEDTLS_SSL_VERIFY_NONE]]传进来的。
|
|
||||||
|
|
||||||
```c
|
|
||||||
int mbedtls_ssl_parse_certificate( mbedtls_ssl_context *ssl )
|
|
||||||
{
|
|
||||||
int ret = 0;
|
|
||||||
int crt_expected;
|
|
||||||
#if defined(MBEDTLS_SSL_SRV_C) && defined(MBEDTLS_SSL_SERVER_NAME_INDICATION)
|
|
||||||
const int authmode = ssl->handshake->sni_authmode != MBEDTLS_SSL_VERIFY_UNSET
|
|
||||||
? ssl->handshake->sni_authmode
|
|
||||||
: ssl->conf->authmode;
|
|
||||||
#else
|
|
||||||
const int authmode = ssl->conf->authmode;
|
|
||||||
#endif
|
|
||||||
void *rs_ctx = NULL;
|
|
||||||
mbedtls_x509_crt *chain = NULL;
|
|
||||||
|
|
||||||
MBEDTLS_SSL_DEBUG_MSG( 2, ( "=> parse certificate" ) );
|
|
||||||
|
|
||||||
crt_expected = ssl_parse_certificate_coordinate( ssl, authmode );
|
|
||||||
if( crt_expected == SSL_CERTIFICATE_SKIP )
|
|
||||||
{
|
|
||||||
MBEDTLS_SSL_DEBUG_MSG( 2, ( "<= skip parse certificate" ) );
|
|
||||||
goto exit;
|
|
||||||
}
|
|
||||||
...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
但是函数`ssl_parse_certificate_coordinate`中又完全不对这个入参做处理,按照逻辑应该判断这个入参是否为`MBEDTLS_SSL_VERIFY_NONE`来判断是否需要返回跳过,这里应该是mbedtls库的一个BUG。
|
|
||||||
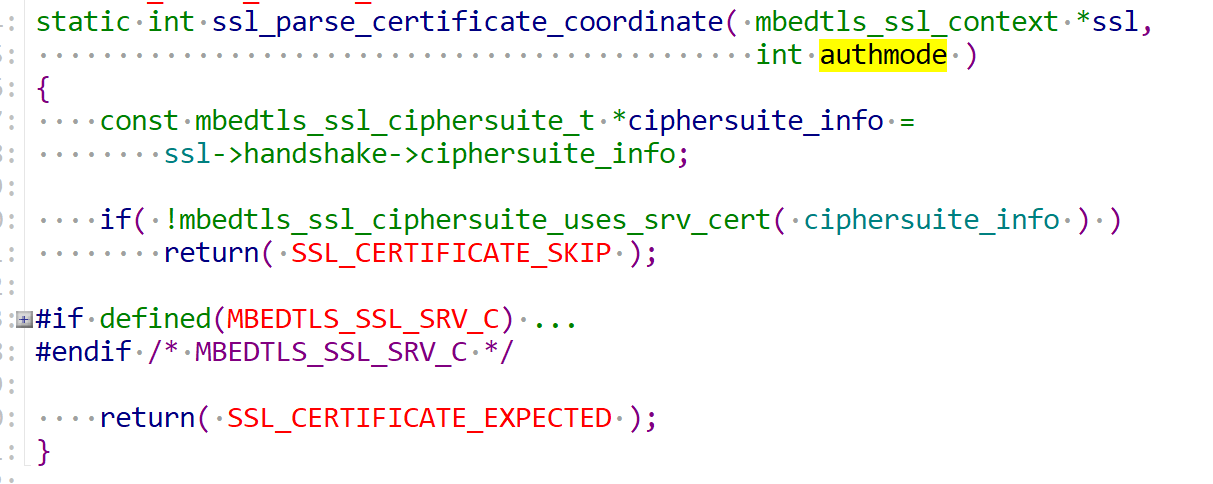
|
|
||||||
尝试在这里让他返回跳过这个证书的步骤,直接到下一个状态。使用抓包工具发现bad certificate的提示消失了,但是出现了新的报错`MBEDTLS_SSL_ALERT_MSG_DECODE_ERROR`,重复上面的过程发现这次在ServerKeyExchange、CertificateRequest、ServerHelloDone都需要相应的手动跳过流程。对mbedtls库的改动过大,应该还有其他的方法可以控制。
|
|
||||||
|
|
||||||
## MBEDTLS_MPI_MAX_SIZE
|
|
||||||
|
|
||||||
观察客户的自签名证书:
|
|
||||||
|
|
||||||
```sh
|
|
||||||
# wyq @ wangyq in ~ [0:19:37]
|
|
||||||
$ openssl x509 -in /mnt/d/cert.pem -text -noout
|
|
||||||
Certificate:
|
|
||||||
Data:
|
|
||||||
Version: 3 (0x2)
|
|
||||||
Serial Number:
|
|
||||||
79:8c:ac:87:c3:92:46:8d:0d:6d:19:16:e7:36:01:47:05:57:25:5f
|
|
||||||
Signature Algorithm: sha256WithRSAEncryption
|
|
||||||
Issuer: C=my, ST=ev, L=kl, O=ev, OU=ev
|
|
||||||
Validity
|
|
||||||
Not Before: Nov 18 14:19:18 2024 GMT
|
|
||||||
Not After : Nov 18 14:19:18 2025 GMT
|
|
||||||
Subject: C=my, ST=ev, L=kl, O=ev, OU=ev
|
|
||||||
Subject Public Key Info:
|
|
||||||
Public Key Algorithm: rsaEncryption
|
|
||||||
Public-Key: (4096 bit)
|
|
||||||
Modulus:
|
|
||||||
00:b7:63:d6:ef:50:65:04:a1:24:67:b3:24:7d:6f:
|
|
||||||
45:6e:16:f6:40:ca:3c:c5:a7:9b:86:5f:42:b9:6f:
|
|
||||||
73:68:06:89:cb:7f:3d:c4:51:c3:c9:0d:c2:68:5b:
|
|
||||||
c9:f1:a1:22:6c:0f:39:5a:51:9e:ed:de:0a:83:11:
|
|
||||||
0f:96:14:e2:7f:b4:92:1d:0a:97:e8:32:c7:60:f9:
|
|
||||||
ad:cb:87:bc:0f:e5:05:8b:4b:6b:71:5f:5a:82:69:
|
|
||||||
b5:09:8e:41:98:9f:de:af:26:d7:2b:db:60:b6:39:
|
|
||||||
7c:e2:0f:98:51:c9:6c:ad:0e:7a:5d:61:5e:6e:4d:
|
|
||||||
fc:49:62:23:92:10:81:ec:23:cb:38:50:b7:b6:b0:
|
|
||||||
b7:77:0d:1d:59:4c:0f:f4:0e:e6:ae:d8:d2:da:51:
|
|
||||||
41:54:86:a1:91:1d:74:7c:a1:00:29:62:25:0e:fd:
|
|
||||||
e8:c5:4a:f1:53:7b:56:01:6f:67:02:ab:6b:77:c0:
|
|
||||||
be:b3:57:75:50:c3:db:6d:03:e8:db:a7:54:2f:bc:
|
|
||||||
2a:94:88:5f:3e:47:b9:61:c6:5b:0d:68:a4:18:f1:
|
|
||||||
3f:df:0d:ab:54:1a:05:8c:25:0b:5c:ce:b2:80:39:
|
|
||||||
ac:fe:94:2f:64:c2:bb:f7:1c:42:e7:08:15:30:b8:
|
|
||||||
33:ba:4e:13:56:1f:82:2a:74:98:e3:5c:8b:4d:6a:
|
|
||||||
8f:14:1e:84:49:01:48:9c:14:3d:46:be:56:87:68:
|
|
||||||
8b:db:5f:79:b4:11:ce:5e:da:d5:ab:53:9e:3b:9b:
|
|
||||||
8e:03:e6:46:50:43:32:70:5a:db:08:5d:83:9f:16:
|
|
||||||
37:4b:62:be:d3:d9:ae:ad:59:92:79:cd:0c:d8:e6:
|
|
||||||
5b:b3:94:c9:03:a0:0c:d4:2c:0c:bb:d0:6d:d4:42:
|
|
||||||
61:c1:11:2c:88:63:d4:70:e4:e7:6d:f3:8b:0e:97:
|
|
||||||
14:c8:28:6a:25:07:de:75:36:27:91:71:65:84:bb:
|
|
||||||
c0:fe:8b:89:bb:bd:f2:d4:bd:a2:18:de:2d:fa:eb:
|
|
||||||
14:cb:f8:b4:63:2d:d3:58:ab:93:89:26:f9:d2:db:
|
|
||||||
cf:75:a3:8c:02:22:d5:7f:2a:2e:12:50:34:90:87:
|
|
||||||
ae:9b:b0:44:d7:9f:4d:98:47:e2:cf:8b:2b:a6:23:
|
|
||||||
77:c1:e8:0c:32:48:79:64:0c:c7:b9:b5:c3:d6:72:
|
|
||||||
d3:e9:01:c9:0e:06:01:b4:f3:ac:99:e5:b0:d0:12:
|
|
||||||
04:39:60:ee:e2:e0:4d:05:ed:70:02:22:24:c9:96:
|
|
||||||
01:59:66:ed:4b:b6:2c:e2:d3:3d:c2:52:32:84:1b:
|
|
||||||
08:db:f5:6b:6f:22:09:f0:bb:2a:54:35:c2:09:68:
|
|
||||||
c9:ab:56:19:5a:73:62:7a:a7:06:3c:43:86:ff:69:
|
|
||||||
8c:3d:27
|
|
||||||
Exponent: 65537 (0x10001)
|
|
||||||
X509v3 extensions:
|
|
||||||
X509v3 Subject Key Identifier:
|
|
||||||
34:91:00:5B:0B:15:EF:EB:E6:FC:7D:8A:85:AB:63:B4:C6:EA:3D:1E
|
|
||||||
X509v3 Authority Key Identifier:
|
|
||||||
34:91:00:5B:0B:15:EF:EB:E6:FC:7D:8A:85:AB:63:B4:C6:EA:3D:1E
|
|
||||||
X509v3 Basic Constraints: critical
|
|
||||||
CA:TRUE
|
|
||||||
Signature Algorithm: sha256WithRSAEncryption
|
|
||||||
Signature Value:
|
|
||||||
10:2e:4c:59:e0:50:39:a6:30:b4:cf:d9:0e:8d:d9:3d:7c:04:
|
|
||||||
08:b4:fd:2d:cf:0f:eb:32:ae:21:e2:7d:83:85:68:60:20:ed:
|
|
||||||
f5:8c:bc:f2:52:8c:bd:c9:ee:2a:96:4f:9a:fd:2c:5d:59:dc:
|
|
||||||
13:d9:68:30:cc:b8:27:46:35:10:eb:87:6c:56:4c:a8:60:78:
|
|
||||||
65:f0:1f:73:b9:80:f5:5c:c6:7c:85:75:26:10:46:48:99:d2:
|
|
||||||
87:32:eb:a2:61:1e:ff:2d:7b:15:8d:e4:1e:36:9b:78:56:06:
|
|
||||||
8c:a9:13:01:49:f5:be:50:c3:cb:62:64:66:2d:1e:2f:5a:2d:
|
|
||||||
2d:fc:62:ef:89:5a:91:53:87:67:51:69:9b:c0:5c:43:04:0d:
|
|
||||||
48:2a:12:17:3d:97:ef:9a:9b:be:11:ab:0d:74:6c:44:34:a8:
|
|
||||||
d8:2d:7b:28:be:2c:ff:06:b5:69:14:39:10:96:c0:a8:43:1f:
|
|
||||||
c5:32:8b:79:92:95:19:30:b9:e4:4a:d0:35:7d:ff:ff:24:75:
|
|
||||||
1e:82:d1:7a:e4:c1:4b:11:e2:2b:b3:a3:91:c3:08:40:1e:52:
|
|
||||||
ef:af:14:ad:f0:c7:39:ca:5d:b6:6b:fc:fa:ed:2c:ed:e1:8f:
|
|
||||||
84:e7:9a:a6:21:20:60:e9:aa:cf:a9:cd:37:fc:5a:90:7a:bc:
|
|
||||||
8d:56:77:e5:1f:25:30:fb:4d:ef:fa:c2:ae:34:ac:d1:f4:0b:
|
|
||||||
4d:d0:9c:ba:86:67:1c:9e:fd:4c:8a:c2:3d:f4:91:93:45:59:
|
|
||||||
51:75:b6:0c:63:94:a0:ac:37:dc:b4:28:4f:cb:cb:43:f7:b1:
|
|
||||||
98:87:f7:3c:26:59:71:a3:ea:0e:25:10:b0:32:a0:35:34:73:
|
|
||||||
8a:da:bb:4e:0b:f8:36:d4:2a:86:98:0d:44:0c:9e:5c:59:c7:
|
|
||||||
19:13:3a:2b:ae:91:13:f9:27:5a:89:38:a0:c5:ed:e0:4a:d0:
|
|
||||||
a2:4f:c9:ee:6c:04:14:72:f3:36:73:ae:4c:9f:0d:9b:48:52:
|
|
||||||
30:3b:fd:2f:99:13:3f:e5:23:c7:31:36:16:1c:d1:6c:0a:37:
|
|
||||||
0e:ee:25:03:b1:b1:ac:03:33:10:fd:67:18:1f:b5:64:9d:51:
|
|
||||||
67:b9:d1:5a:c9:ba:90:0d:30:cd:3e:4b:a6:3a:6c:87:5d:48:
|
|
||||||
2b:4a:eb:7e:dc:d7:f9:a3:28:24:cc:47:86:9b:58:cf:bd:e6:
|
|
||||||
fa:cc:95:27:5c:47:2d:a1:e8:3b:61:d4:da:b1:2c:2c:e1:26:
|
|
||||||
a7:40:8b:86:45:c4:84:20:4f:cb:30:29:7c:1b:d5:87:82:38:
|
|
||||||
52:2c:ac:c7:55:ae:98:23:79:ed:2b:b0:1e:99:27:d9:1b:bd:
|
|
||||||
48:dd:61:6c:1e:45:a3:6d
|
|
||||||
```
|
|
||||||
|
|
||||||
发现客户使用的是一个 X.509 第三版的证书,使用 `SHA-256` 哈希算法和 `RSA` 加密算法签名证书,==公钥长度为 4096 位==。
|
|
||||||
|
|
||||||
问题出现了,正经人谁用这么长的公钥?
|
|
||||||
|
|
||||||
根据 [NIST SP 800-57](https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-57pt1r5.pdf) 的建议,不同算法的安全性级别如下:
|
|
||||||
|
|
||||||
| **安全性级别** | **RSA 密钥长度** | **ECC 密钥长度** |
|
|
||||||
| --------- | ------------ | ------------ |
|
|
||||||
| 112 位 | 2048 位 | 224 位 |
|
|
||||||
| 128 位 | 3072 位 | 256 位 |
|
|
||||||
| 192 位 | 7680 位 | 384 位 |
|
|
||||||
| 256 位 | 15360 位 | 512 位 |
|
|
||||||
|
|
||||||
从表中可以看出,RSA 4096 位位于 ECC 384 位和 512 位之间,明明用ecc算法384位就能搞定的事情,非得增加mcu的负担。
|
|
||||||
|
|
||||||
修改`MBEDTLS_MPI_MAX_SIZE`宏从384到512。
|
|
||||||
|
|
||||||
```c
|
|
||||||
#define MBEDTLS_MPI_MAX_SIZE 512
|
|
||||||
```
|
|
||||||
|
|
||||||
# 总结
|
|
||||||
|
|
||||||
这次的无法连接平台的问题,主要是mbedtls中对于tls的握手处理,把是否跳过验证的处理放到了解析证书的后面。导致即使使用`MBEDTLS_SSL_VERIFY_NONE`关闭了验证,实际上却因为`MBEDTLS_MPI_MAX_SIZE`大小不够而导致证书解析失败,从而导致无法连接平台。还有就是对客户平台的不了解,一开始以为客户无法提供自签名的证书,也没有想到客户不是使用主流的2048位的公钥的RSA签名。
|
|
||||||
@ -1,35 +0,0 @@
|
|||||||
---
|
|
||||||
date created: 2024-10-29 17:12
|
|
||||||
date updated: 2024-10-29 17:26
|
|
||||||
share: "true"
|
|
||||||
path: content
|
|
||||||
en-filename: index
|
|
||||||
title: 首页
|
|
||||||
updated: 2024-12-05 15:48
|
|
||||||
publish: true
|
|
||||||
---
|
|
||||||
|
|
||||||
# 目录
|
|
||||||
|
|
||||||
[[Obsidian/|目录]]
|
|
||||||
|
|
||||||
# 最近更新
|
|
||||||
|
|
||||||
| File | 目录 | 更新时间 |
|
|
||||||
| ---------------------------------------------------------------------------------- | ------------------ | ---------------------------- |
|
|
||||||
| [[./Obsidian/工具/笔记/如何在 Obsidian 中优雅的进行注释(边注)\|如何在 Obsidian 中优雅的进行注释(边注)]] | Obsidian/工具/笔记 | 4:46 PM - December 09, 2024 |
|
|
||||||
| [[./Obsidian/工具/笔记/Obsidian配置\|Obsidian配置]] | Obsidian/工具/笔记 | 5:24 PM - December 05, 2024 |
|
|
||||||
| [[./Obsidian/工具/笔记/使用Quartz部署obsidian\|使用Quartz部署obsidian]] | Obsidian/工具/笔记 | 5:23 PM - December 05, 2024 |
|
|
||||||
| [[./Obsidian/工具/笔记/dataview的简单使用\|dataview的简单使用]] | Obsidian/工具/笔记 | 11:34 AM - December 05, 2024 |
|
|
||||||
| [[./Typora/以太网/ping过程\|ping过程]] | Typora/以太网 | 11:59 AM - December 04, 2024 |
|
|
||||||
| [[./Obsidian/踩过的坑/以太网BUG解决过程记录\|以太网BUG解决过程记录]] | Obsidian/踩过的坑 | 9:55 PM - December 03, 2024 |
|
|
||||||
| [[./Obsidian/环境搭建/调试/MPU版本烧写\|MPU版本烧写]] | Obsidian/环境搭建/调试 | 9:46 PM - December 03, 2024 |
|
|
||||||
| [[./Obsidian/后端/动态代理\|动态代理]] | Obsidian/后端 | 9:46 PM - December 03, 2024 |
|
|
||||||
| [[./Obsidian/后端/反射机制\|反射机制]] | Obsidian/后端 | 9:46 PM - December 03, 2024 |
|
|
||||||
| [[./Obsidian/后端/spring\|spring]] | Obsidian/后端 | 9:45 PM - December 03, 2024 |
|
|
||||||
| [[./Obsidian/工具/flac批量转换成mp3\|flac批量转换成mp3]] | Obsidian/工具 | 9:45 PM - December 03, 2024 |
|
|
||||||
| [[./Obsidian/工具/笔记/卢曼的卡片盒笔记法:Zettelkasten Method\|卢曼的卡片盒笔记法:Zettelkasten Method]] | Obsidian/工具/笔记 | 9:45 PM - December 03, 2024 |
|
|
||||||
| [[./Obsidian/编程语言/Java/JDBC\|JDBC]] | Obsidian/编程语言/Java | 9:44 PM - December 03, 2024 |
|
|
||||||
| [[./Obsidian/编程模型及方法/依赖注入\|依赖注入]] | Obsidian/编程模型及方法 | 9:44 PM - December 03, 2024 |
|
|
||||||
| [[./Obsidian/编程模型及方法/ORM\|ORM]] | Obsidian/编程模型及方法 | 9:44 PM - December 03, 2024 |
|
|
||||||
|
|
||||||
Loading…
Reference in New Issue
Block a user